Local Data Tutorial¶
In this tutorial, rather than running real models and configurations over MIMIC-IV, we’ll work with a set of local, synthetic files distributed with this repository, with the goal being to fully explore the details of this pipeline. This tutorial will consist of both content on this page, running certain scripts on one’s local machine, and some jupyter notebooks. We will walk through the entire pipeline with these local examples and discuss limitations of the pipeline, details of classes, scripts, etc.
We’ll use rootutils to ensure that our notebook is running from the root of the ESGPT repository, to make imports easier. We also delete any previously processed data from this tutorial, to keep things isolated to this run. Do not re-run this cell unless you want to re-run the full tutorial.
[1]:
import os
import rootutils
import shutil
root = rootutils.setup_root(os.path.abspath(''), dotenv=True, pythonpath=True, cwd=True)
shutil.rmtree('sample_data/processed', ignore_errors=True)
Synthetic Data¶
For this tutorial, we’ll use the three synthetic data files distributed in the sample_data/raw folder in the repository:
[2]:
!ls --color sample_data/raw
admit_vitals.csv labs.csv medications.csv subjects.csv
To see how those files are generated, look at sample_data/generate_synthetic_data.py
These files contain the following data:
subjects.csv¶
This file contains per-subject data. It has one row per subject, with each row containing a subject identifier (here called “MRN”), a date of birth (”dob”), the subject’s eye color (eye_color), and the subject’s height (”height”):
[3]:
import polars as pl
pl.Config.set_tbl_cols(7)
display(pl.read_csv('sample_data/raw/subjects.csv').head(4))
| MRN | dob | eye_color | height |
|---|---|---|---|
| i64 | str | str | f64 |
| 310243 | "07/28/1981" | "GREEN" | 178.767932 |
| 384198 | "04/15/1985" | "BROWN" | 168.319295 |
| 520533 | "04/15/1979" | "BROWN" | 165.836447 |
| 850710 | "08/08/1970" | "HAZEL" | 159.721833 |
admit_vitals.csv¶
This file contains dynamic data quantifying both fictional subject hospital admissions, and fictional vitals signs measured for those subjects. Each row of this file records a unique vitals sign measurement for a patient, affiliated with the associated admission listed in the row. This means that admission level information is heavily duplicated within this file, which is a phenomena sometimes observed in real data, and something we’ll need to account for in our pipeline’s setup.
[4]:
display(pl.read_csv('sample_data/raw/admit_vitals.csv').head(4))
| MRN | admit_date | disch_date | department | vitals_date | HR | temp |
|---|---|---|---|---|---|---|
| i64 | str | str | str | str | f64 | f64 |
| 1549363 | "01/04/2010, 06… | "01/14/2010, 11… | "ORTHOPEDIC" | "01/11/2010, 14… | 77.1 | 96.3 |
| 415881 | "02/11/2010, 04… | "02/14/2010, 07… | "ORTHOPEDIC" | "02/11/2010, 10… | 148.5 | 95.6 |
| 42335 | "03/06/2010, 05… | "03/16/2010, 05… | "CARDIAC" | "03/13/2010, 10… | 46.7 | 101.0 |
| 1516810 | "02/11/2010, 23… | "02/22/2010, 23… | "CARDIAC" | "02/12/2010, 16… | 94.2 | 95.2 |
labs.csv¶
This file contains dynamic data quantifying fictional subject laboratory test measurements. Each row of this file contains a record of a particular lab test measured for a subject. Note that the lab data is not organized into separate columns for each lab; rather each row contains a pair of a lab test name and the associated value; this is what we call in ESGPT a “multivariate regression” column encoding.
[5]:
display(pl.read_csv('sample_data/raw/labs.csv').head(4))
| MRN | timestamp | lab_name | lab_value |
|---|---|---|---|
| i64 | str | str | f64 |
| 1006798 | "10:26:00-2010-… | "SpO2" | 53.0 |
| 739156 | "20:45:44-2010-… | "SpO2" | 51.0 |
| 426870 | "00:25:02-2010-… | "SpO2" | 50.0 |
| 338121 | "17:19:16-2010-… | "GCS" | 1.0 |
Processing Synthetic Data with ESGPT¶
Now that we see the form of this synthetic data, we can examine how to process it with Event Stream GPT. From the base directory of the ESGPT repository, we can run the following command:
PYTHONPATH=$(pwd):$PYTHONPATH ./scripts/build_dataset.py \
--config-path="$(pwd)/sample_data/" \
--config-name=dataset \
"hydra.searchpath=[$(pwd)/configs]"
Note that this script, like all built-in ESGPT scripts, uses Hydra, a configuration file and experiment run-script library. In hydra, all scripts can take as input a set of composable configuration files which can be overwritten via files or via the command line. If you aren’t already familiar with Hydra, you should read through some of their examples or tutorials to gain some familiarity with their system.
Before we actually run this command, we need to do 2 things:
Decide what we want the command to do, conceptually.
Understand what we’re telling the library to do, via its input arguments.
What do we want to happen?¶
We can see that our synthetic data has a few different kinds of things happening to these subjects. In the ESGPT data model, we want to organize this data so that we clearly know who our subjects are, quantify when things happen to those subjects, and record in a sparse manner what is happening to those patients. Let’s list a few more specific desiderata:
We should expect our system to quantify those subjects in our synthetic data that meet our inclusion criteria (which we haven’t yet specified).
The system should bucket all interactions for subjects into appropriately defined events, across admissions, discharges, vitals signs, and laboratory tests.
The system should learn appropriate categorical vocabularies, numerical outlier detector models, numerical normalization models, for the various measurements we want to extract (which we haven’t yet specified).
The system should produce “deep-learning friendly” representations of these data.
A quick tangent – what do we mean by “deep-learning friendly” representations of these data? Well, right now, if we were to try to run these data through any deep-learning system for longitudinal data, we’d need to re-format these data such that it is easy to efficiently (ideally \(O(1)\)) retrieve all data corresponding to a single subject in an organized timeseries format that we can then efficiently (meaning in a manner requiring minimal GPU memory) pass into a sequential neural network.
In the current representation, this retrieval process would not be \(O(1)\); instead, if we didn’t modify the data’s organization at all, for each new MRN, we’d need to select from each data file all those rows with that MRN (each selection being an \(O(N)\) operation), and then we would need to subsequently sort all the temporal data by timestamp (another \(O(L\ln(L))\) operation).
Similarly, if we use a naive, dense encoding of the data per measurement for our DL representation, this will be very wasteful in terms of GPU memory, as each record will need to occupy memory proportionate to the total number of possible measurements we could observe in our data (e.g., the total number of lab tests, plus the total number of vitals signs, plus the total number of admission departments, etc.). Instead, a sparse encoding should be used.
These two properties are exactly what we mean by a “deep-learning friendly” representation of the data.
We can see that there are several questions posed by these desiderata that we need to answer, such as:
What are our inclusion criteria?
How should we bucket interactions into events?
What measurements do we want to extract?
How do we want to define “outliers”?
How do we define “appropriate categorical vocabularies”?
How do we want to normalize numerical measurements?
To start us off, let’s use the following answers:
We’ll include all subjects who have at least 3 events, with no other inclusion/exclusion criteria.
We’ll define an “event” to be any interactions happening to a patient within a 1 hour period. We’ll bucket these interactions together starting at the earliest event.
Ideally, we’d like to extract all measurements. As we’ll see, however, due to a limitation in the current version of ESGPT, we’ll extract all measurements except for the patient’s height. In particular, we’ll extract the occurrence of admissions, discharges, vitals signs, and laboratory tests, as well as the subject’s age, eye color, admission department, the values recorded for HR and temperature, and all lab test values.
We’ll use a very simple outlier model, that excludes numerical data as outliers if their values exceed 1.5 standard deviations from the mean. This is an extremely aggressive cutoff only suitable for this synthetic data setting.
We’ll keep any categorical observation as a vocabulary element if it occurs at least 5 times.
We’ll normalize our numerical observations to have zero mean and unit variance.
Telling the pipeline what to do: input config¶
Now that we have some basic idea of what we want the pipeline to do, let’s examine the input configuration file that we pass to the dataset script:
[6]:
!cat sample_data/dataset.yaml
defaults:
- dataset_base
- _self_
# So that it can be run multiple times without issue.
do_overwrite: True
cohort_name: "sample"
subject_id_col: "MRN"
raw_data_dir: "./sample_data/raw/"
save_dir: "./sample_data/processed/${cohort_name}"
DL_chunk_size: null
inputs:
subjects:
input_df: "${raw_data_dir}/subjects.csv"
admissions:
input_df: "${raw_data_dir}/admit_vitals.csv"
start_ts_col: "admit_date"
end_ts_col: "disch_date"
ts_format: "%m/%d/%Y, %H:%M:%S"
event_type: ["OUTPATIENT_VISIT", "ADMISSION", "DISCHARGE"]
vitals:
input_df: "${raw_data_dir}/admit_vitals.csv"
ts_col: "vitals_date"
ts_format: "%m/%d/%Y, %H:%M:%S"
labs:
input_df: "${raw_data_dir}/labs.csv"
ts_col: "timestamp"
ts_format: "%H:%M:%S-%Y-%m-%d"
medications:
input_df: "${raw_data_dir}/medications.csv"
ts_col: "timestamp"
ts_format: "%H:%M:%S-%Y-%m-%d"
columns: {"name": "medication"}
measurements:
static:
single_label_classification:
subjects: ["eye_color"]
functional_time_dependent:
age:
functor: AgeFunctor
necessary_static_measurements: { "dob": ["timestamp", "%m/%d/%Y"] }
kwargs: { dob_col: "dob" }
dynamic:
multi_label_classification:
admissions: ["department"]
medications:
- name: medication
modifiers:
- [dose, "float"]
- [frequency, "categorical"]
- [duration, "categorical"]
- [generic_name, "categorical"]
univariate_regression:
vitals: ["HR", "temp"]
multivariate_regression:
labs: [["lab_name", "lab_value"]]
outlier_detector_config:
stddev_cutoff: 1.5
min_valid_vocab_element_observations: 5
min_valid_column_observations: 5
min_true_float_frequency: 0.1
min_unique_numerical_observations: 20
min_events_per_subject: 3
agg_by_time_scale: "1h"
There are a number of sections in this file. Firstly, the first three lines ensure this config builds on the defaults provided with the ESGPT library, via Hydra’s normal mechanisms. If you aren’t familiar with this syntax, check out the Hydra documentation.
Next, there is a section defining some overarching variables and a section defining our input sources. We can see this section details the paths to each of our input files as well as the formatting used for (most of) the timestamps within these files. Note that this section makes use of Hydra/OmegaConf’s Interpolations to simplify the specification of the file paths used.
Warning: Two parameters in this section are required: subject_id_col, and cohort_name. This will be explored in more detail later in this tutorial.
Next, we have a section defining the various measurements we’ll exctract in this dataset. We can see we specify each of the measurements we discussed above:
eye_coloris extracted as astatic,single_label_classificationmeasure.ageis extracted as afunctional_time_dependentmeasure, leveraging the date-of-birth columndob. Note that this is where we define the timestamp format for the ``dob`` column, as it is a timestamp formatted static column!departmentis extracted as adynamic,multi_label_classificationmeasure.HR, andtempare extracted asdynamic,univariate_regressionmeasures.lab_nameandlab_valueare extracted as a singledynamic,multivariate_regressionmeasure.
Note that the terms static, functional_time_dependent, & dynamic and single_label_classification, multi_label_classification, univariate_regression, and multivariate_regression, are defined enumerations in the EventStream.data.config sub-module, and dictate where measurements are stored and how they are pre-processed.
Finally, we have the remaining set of parameters, which define our inclusion-exclusion criteria (by specifying min_events_per_subject), our outlier detection parameters, our filtering thresholds for vocabulary elements, and the aggregation time-scale for events.
What else could we have specified?¶
To better understand the structure of this input specification, let’s explore this input configuration file in a bit more detail. To start with, let’s look at what the default, base config contains (the config we inherit from in the defaults list):
[7]:
!cat configs/dataset_base.yaml
defaults:
- outlier_detector_config: stddev_cutoff
- _self_
cohort_name: ???
save_dir: ${oc.env:PROJECT_DIR}/data/${cohort_name}
subject_id_col: ???
seed: 1
split: [0.8, 0.1]
do_overwrite: False
DL_chunk_size: 20000
min_valid_vocab_element_observations: 25
min_valid_column_observations: 50
min_true_float_frequency: 0.1
min_unique_numerical_observations: 25
min_events_per_subject: 20
agg_by_time_scale: null
center_and_scale: True
hydra:
job:
name: build_${cohort_name}
run:
dir: ${save_dir}/.logs
sweep:
dir: ${save_dir}/.logs
We can see there are some parameters we’re familiar with and some we’re not. Firstly, we can see that this default base config marks cohort_name and subject_id_col with ???. This is the OmegaConf provided value to represent a value that needs to be overwritten in downstream usage. This is why those two parameters are mandatory. This config also has variables for the seed, split size, and some hydra-internal parameters. There is also a nested config for the standard deviation cutoff
for outlier detection.
[8]:
!cat configs/outlier_detector_config/stddev_cutoff.yaml
stddev_cutoff: 5.0
These are both quite simple, but show how the final config will be constructed from these values.
One thing that is notably missing from this broader structure is any notion of included inputs or measurements sections. To understand how we can further specify our config, we need to understand how we could modify those sections as well.
Inputs¶
This section allows us to specify which input data frames should be read, and from where. The inputs: option should be an object whose keys are the names of input sources and whose values are configuration for those inputs. Currently, two input formats are possible:
The
input_dfformat, which is used in this synthetic example. This format has an input configuration that contains theinput_df:key whose value is a file path pointing to acsvorparquetdata-frame file on disk that contains that input source’s data. For example:
admissions:
input_df: "${raw_data_dir}/admit_vitals.csv"
start_ts_col: "admit_date"
end_ts_col: "disch_date"
ts_format: "%m/%d/%Y, %H:%M:%S"
event_type: ["OUTPATIENT_VISIT", "ADMISSION", "DISCHARGE"]
The
queryformat, which is used in the MIMIC-IV tutorial. In this format, you must specify aqueryparameter. This parameter can either be a string query or a list of string queries, in which case you must specify a globalconnection_uriparameter detailing the URI of the database to which you wish to query (In the connector-x format), or a dictionary, with keys and values specifying parameters of the`EventStream.data.dataset_polars.Query<>`__ object. For example:
patients:
query: |-
SELECT subject_id, gender, to_date((anchor_year-anchor_age)::CHAR(4), 'YYYY') AS year_of_birth
FROM mimiciv_hosp.patients
WHERE subject_id IN (
SELECT long_icu.subject_id FROM (
(
SELECT subject_id FROM mimiciv_icu.icustays WHERE los > ${min_los}
) AS long_icu INNER JOIN (
SELECT subject_id
FROM mimiciv_hosp.admissions
GROUP BY subject_id
HAVING COUNT(*) > ${min_admissions}
) AS many_admissions
ON long_icu.subject_id = many_admissions.subject_id
)
)
must_have: ["gender", "year_of_birth"]
Each input can also have a number of other keys and values, including:
Timestamp & Event-type Specification.
For non-static data sources, the keys ts_col or start_ts_col and end_ts_col specify the name of the column (or columns) containing the timestamp for the event, and ts_format the format of that timestamp. ts_col is used for data-sources where each row represents one event, and start_/end_ts_col for data-sources where each row specifies a range in time. For example, in our synthetic config,
admissions:
input_df: "${raw_data_dir}/admit_vitals.csv"
start_ts_col: "admit_date"
end_ts_col: "disch_date"
ts_format: "%m/%d/%Y, %H:%M:%S"
event_type: ["OUTPATIENT_VISIT", "ADMISSION", "DISCHARGE"]
specifies a range event, where the start timestamp is stored in admit_date and the end timestamp in disch_date, formatted as "%m/%d/%Y, %H:%M:%S". In contrast,
labs:
input_df: "${raw_data_dir}/labs.csv"
ts_col: "timestamp"
ts_format: "%H:%M:%S-%Y-%m-%d"
captures data where each row is a single-timepoint event, with timestamp stored in "%H:%M:%S-%Y-%m-%d" format in column timestamp.
You can also explicitly set the type of each event. Events’ types in ESGPT are categorical variables defined by the user that are used to dictate any intra-event causal dependency graphs in downstream models, can be used to help define downstream tasks, and are otherwise used to analyze and describe data. When using the pre-defined build dataset script, they can either be explicitly set or are automatically inferred from the name of the input block. For example, in the examples given above, the
labs: block produces an input source with the event type LAB (the singular, upper-cased inflection of the name of the block, 'labs'), and admissions (being a range event) produces events of type 'OUTPATIENT_VISIT' when admit_date == disch_date and 'ADMISSION' on admit_date and 'DISCHARGE' on disch_date. For range events, the default event types are defined to be *_EQ, *_START, and *_END, where * is the singular, upper-cased inflection of
the input block name.
Event types can also be defined to be column dependent. For example, in this config example (which is not part of our current synthetic example config), we see that event types are defined to take on the value of the column 'visit_occurrence_concept_name' for the case that the start and end times are the same and for start events, but the static 'Drug Stop' for end events.
drugs:
input_df: "${raw_data_dir}/drug.parquet"
start_ts_col: "drug_exposure_start_datetime"
end_ts_col: ["drug_exposure_end_datetime", "verbatim_end_date"]
event_type: ["COL:visit_occurrence_concept_name", "COL:visit_occurrence_concept_name", "Drug Stop"]
start_columns: {"standard_concept_name": "drug", "drug_type_concept_name": "drug_type"}
end_columns:
standard_concept_name: drug
drug_type_concept_name: drug_type
stop_reason: drug_stop_reason
Filtering
You can also specify a simple filter used for a given input source. For example, in the patients block in the MIMIC-IV example, we specify that valid rows must have 'gender' and 'year_of_birth' defined and non-null. This is another way to enforce cohort inclusion/exclusion criteria. The filter object can either be a list of strings, in which case those columns must have non-null values, or a dictionary from column names to either the boolean True (indicating the column must be
present and non-null) or lists of allowable values for that column.
Measurement columns to extract
You can also specify which measurements should be extracted to associate with a given input data source. Largely, this information will be determined automatically based on the measurements section of the config; however, it can be specified explicitly as well. The most common case this would be done is to differentiate different measurements to associate with start and end events for range events or to re-name measurements from their input column names to new names for internal use
(this can be done not only for cosmetic reasons, but so as to unify or disentangle measurements across different input files). For example, in the drugs: example shown above, the columns standard_concept_name and drug_type_concept_name are both used for both start and end events, and are renamed to 'drug', and 'drug_type' in both cases, whereas stop_reason is used only for end events (and is renamed to drug_stop_reason). ##### Measurements Section The
measurements: block lists all the actual measurements that should be extracted from those input sources, broken down into categories based on their temporality and modality (see EventStream.data.types.TemporalityType and EventStream.data.types.DataModality, respectively).
The only non-standard portion of this block corresponds to the functional_time_dependent block, which specifies measurements whose values are not stored in the raw input data by default, but are instead computable dynamically given per-subject static data and the timestamps of other events that occur in the data. A good example is a subject’s age, which is included in our synthetic configuration. Given a subject’s date-of-birth and the timestamp of any other event, we can dynamically
compute the subject’s age as of that event, which is exactly what the EventStream.data.time_dependent_functor.AgeFunctor does.
The structure of this config section is
functional_time_dependent:
output_measurement_name:
functor: ??? # The functor that is used for this measurement. Must be in `EventStream.data.config.MeasurementConfig.FUNCTORS`
necessary_static_measurements: { "static_measurement_column": ??? } # column name: column formatting info
kwargs: { kwarg: kwval } # Keyword args to pass to functor constructor.
Currently, only `AgeFunctor <>`__ and [TimeOfDayFunctor] are pre-defined and supported, but this can be extended by the user by directly adding new functors to the `EventStream.data.config.MeasurementConfig <>`__ object.
Running the Command¶
Now that we understand the setup a bit better, let’s run the actual command:
PYTHONPATH=$(pwd):$PYTHONPATH ./scripts/build_dataset.py \
--config-path="$(pwd)/sample_data/" \
--config-name=dataset \
"hydra.searchpath=[$(pwd)/configs]"
To make this notebook self sufficient, we’ll run it here via the `subprocess <>`__ module:
[9]:
import subprocess
command = """\
PYTHONPATH=$(pwd):$PYTHONPATH ./scripts/build_dataset.py \
--config-path="$(pwd)/sample_data/" \
--config-name=dataset \
"hydra.searchpath=[$(pwd)/configs]" """
command_out = subprocess.run(command, shell=True, capture_output=True)
print(command_out.stdout.decode())
if command_out.returncode == 1:
print("Command Errored!")
print(command_out.stderr.decode())
2024-05-16 13:22:36.817 | DEBUG | EventStream.data.dataset_polars:_load_input_df:177 - Loading df from ./sample_data/raw//subjects.csv
2024-05-16 13:22:36.819 | DEBUG | EventStream.data.dataset_base:__init__:475 - Extracting events and measurements dataframe...
2024-05-16 13:22:36.819 | DEBUG | EventStream.data.dataset_polars:_load_input_df:177 - Loading df from ./sample_data/raw//admit_vitals.csv
2024-05-16 13:22:36.819 | DEBUG | EventStream.data.dataset_base:build_event_and_measurement_dfs:242 - Processing Range
2024-05-16 13:22:36.819 | DEBUG | EventStream.data.dataset_polars:_process_events_and_measurements_df:313 - Processing OUTPATIENT_VISIT via {'department': ('department', <InputDataType.CATEGORICAL: 'categorical'>)}
2024-05-16 13:22:36.820 | DEBUG | EventStream.data.dataset_polars:_process_events_and_measurements_df:313 - Processing ADMISSION via {'department': ('department', <InputDataType.CATEGORICAL: 'categorical'>)}
2024-05-16 13:22:36.821 | DEBUG | EventStream.data.dataset_polars:_process_events_and_measurements_df:313 - Processing DISCHARGE via {'department': ('department', <InputDataType.CATEGORICAL: 'categorical'>)}
2024-05-16 13:22:36.821 | DEBUG | EventStream.data.dataset_base:build_event_and_measurement_dfs:231 - Processing Event
2024-05-16 13:22:36.821 | DEBUG | EventStream.data.dataset_polars:_process_events_and_measurements_df:313 - Processing VITAL via {'HR': ('HR', <InputDataType.FLOAT: 'float'>), 'temp': ('temp', <InputDataType.FLOAT: 'float'>)}
2024-05-16 13:22:36.822 | DEBUG | EventStream.data.dataset_polars:_load_input_df:177 - Loading df from ./sample_data/raw//labs.csv
2024-05-16 13:22:36.822 | DEBUG | EventStream.data.dataset_base:build_event_and_measurement_dfs:231 - Processing Event
2024-05-16 13:22:36.822 | DEBUG | EventStream.data.dataset_polars:_process_events_and_measurements_df:313 - Processing LAB via {'lab_name': ('lab_name', <InputDataType.CATEGORICAL: 'categorical'>), 'lab_value': ('lab_value', <InputDataType.FLOAT: 'float'>)}
2024-05-16 13:22:36.823 | DEBUG | EventStream.data.dataset_polars:_load_input_df:177 - Loading df from ./sample_data/raw//medications.csv
2024-05-16 13:22:36.823 | DEBUG | EventStream.data.dataset_base:build_event_and_measurement_dfs:231 - Processing Event
2024-05-16 13:22:36.823 | DEBUG | EventStream.data.dataset_polars:_process_events_and_measurements_df:313 - Processing MEDICATION via {'name': ('medication', <InputDataType.CATEGORICAL: 'categorical'>), 'dose': ('dose', 'float'), 'frequency': ('frequency', 'categorical'), 'duration': ('duration', 'categorical'), 'generic_name': ('generic_name', 'categorical')}
2024-05-16 13:22:36.825 | DEBUG | EventStream.data.dataset_base:__init__:480 - Built events and measurements dataframe
2024-05-16 13:22:36.827 | DEBUG | EventStream.data.dataset_polars:_agg_by_time:642 - Collecting events DF. Not using streaming here as it sometimes causes segfaults.
2024-05-16 13:22:36.859 | DEBUG | EventStream.data.dataset_polars:_agg_by_time:649 - Aggregating timestamps into buckets
2024-05-16 13:22:36.915 | DEBUG | EventStream.data.dataset_polars:_agg_by_time:684 - Re-mapping measurements df
2024-05-16 13:22:36.947 | DEBUG | EventStream.data.dataset_polars:_validate_initial_df:540 - Validating subject_id
2024-05-16 13:22:36.949 | DEBUG | EventStream.data.dataset_polars:_validate_initial_df:540 - Validating event_id
2024-05-16 13:22:36.959 | DEBUG | EventStream.data.dataset_polars:_update_subject_event_properties:695 - Collecting event types
2024-05-16 13:22:36.962 | DEBUG | EventStream.data.dataset_polars:_update_subject_event_properties:708 - Collecting subject event counts
2024-05-16 13:22:36.963 | INFO | EventStream.data.dataset_base:preprocess:722 - Filtering subjects
2024-05-16 13:22:36.969 | INFO | EventStream.data.dataset_base:preprocess:724 - Adding time derived measurements
2024-05-16 13:22:36.970 | INFO | EventStream.data.dataset_base:preprocess:726 - Fitting pre-processing parameters
2024-05-16 13:22:37.080 | INFO | EventStream.data.dataset_base:preprocess:728 - Transforming variables.
2024-05-16 13:22:37.202 | INFO | EventStream.data.dataset_base:preprocess:730 - Done with preprocessing
2024-05-16 13:22:37.235 | INFO | EventStream.data.dataset_base:cache_deep_learning_representation:1363 - Caching DL representations
2024-05-16 13:22:37.236 | WARNING | EventStream.data.dataset_base:cache_deep_learning_representation:1365 - Sharding is recommended for DL representations.
2024-05-16 13:22:37.236 | INFO | EventStream.data.dataset_base:cache_deep_learning_representation:1403 - Caching train/0 to sample_data/processed/sample/DL_reps/train/0.parquet
2024-05-16 13:22:37.316 | INFO | EventStream.data.dataset_base:cache_deep_learning_representation:1412 - Caching NRT for train/0 to sample_data/processed/sample/NRT_reps/train/0.pt
2024-05-16 13:22:37.684 | INFO | EventStream.data.dataset_base:cache_deep_learning_representation:1403 - Caching held_out/0 to sample_data/processed/sample/DL_reps/held_out/0.parquet
2024-05-16 13:22:37.704 | INFO | EventStream.data.dataset_base:cache_deep_learning_representation:1412 - Caching NRT for held_out/0 to sample_data/processed/sample/NRT_reps/held_out/0.pt
2024-05-16 13:22:37.742 | INFO | EventStream.data.dataset_base:cache_deep_learning_representation:1403 - Caching tuning/0 to sample_data/processed/sample/DL_reps/tuning/0.parquet
2024-05-16 13:22:37.758 | INFO | EventStream.data.dataset_base:cache_deep_learning_representation:1412 - Caching NRT for tuning/0 to sample_data/processed/sample/NRT_reps/tuning/0.pt
You should see the output logs and the command complete successfully. Before we proceed further, let’s break down what this process has done, and how it could do things differently.
Firstly, let’s take a look at what is produced in the output folder itself.
[10]:
!du -sh sample_data/processed/sample/
4.5M sample_data/processed/sample/
[11]:
!ls --color -R sample_data/processed/sample
sample_data/processed/sample:
config.json inferred_measurement_configs.json
DL_reps inferred_measurement_metadata
DL_shards.json input_schema.json
dynamic_measurements_df.parquet NRT_reps
E.pkl subjects_df.parquet
events_df.parquet vocabulary_config.json
hydra_config.yaml
sample_data/processed/sample/DL_reps:
held_out train tuning
sample_data/processed/sample/DL_reps/held_out:
0.parquet
sample_data/processed/sample/DL_reps/train:
0.parquet
sample_data/processed/sample/DL_reps/tuning:
0.parquet
sample_data/processed/sample/inferred_measurement_metadata:
age.csv HR.csv lab_name.csv temp.csv
sample_data/processed/sample/NRT_reps:
held_out train tuning
sample_data/processed/sample/NRT_reps/held_out:
0.pt
sample_data/processed/sample/NRT_reps/train:
0.pt
sample_data/processed/sample/NRT_reps/tuning:
0.pt
Now, let’s walk through what happens when we run this script, step-by-step, and how each of the files listed above are produced.
Step 1: Config Parsing¶
First, the script parses our input config file into a slightly refined structured form, then passes that as input to the EventStream.data.dataset_polars.Dataset constructor.
To see what this process looks like, we can inspect one portion of the output of the overall script, which we can find in the `sample_data/processed/sample <>`__ directory; in particular, the input_schema.json file.
Note that the sample_data/processed/sample directory is the save_dir key in our dataset.yaml configuration file.
[12]:
!cat sample_data/processed/sample/input_schema.json | python -m json.tool
{
"static": {
"input_df": "./sample_data/raw//subjects.csv",
"type": "static",
"event_type": null,
"subject_id_col": "MRN",
"ts_col": null,
"start_ts_col": null,
"end_ts_col": null,
"ts_format": null,
"start_ts_format": null,
"end_ts_format": null,
"data_schema": [
{
"eye_color": "categorical",
"dob": [
"dob",
[
"timestamp",
"%m/%d/%Y"
]
]
}
],
"start_data_schema": null,
"end_data_schema": null,
"must_have": []
},
"dynamic": [
{
"input_df": "./sample_data/raw//admit_vitals.csv",
"type": "range",
"event_type": [
"OUTPATIENT_VISIT",
"ADMISSION",
"DISCHARGE"
],
"subject_id_col": "MRN",
"ts_col": null,
"start_ts_col": "admit_date",
"end_ts_col": "disch_date",
"ts_format": null,
"start_ts_format": "%m/%d/%Y, %H:%M:%S",
"end_ts_format": "%m/%d/%Y, %H:%M:%S",
"data_schema": [
{
"department": "categorical"
}
],
"start_data_schema": [
{
"department": "categorical"
}
],
"end_data_schema": [
{
"department": "categorical"
}
],
"must_have": []
},
{
"input_df": "./sample_data/raw//admit_vitals.csv",
"type": "event",
"event_type": "VITAL",
"subject_id_col": "MRN",
"ts_col": "vitals_date",
"start_ts_col": null,
"end_ts_col": null,
"ts_format": "%m/%d/%Y, %H:%M:%S",
"start_ts_format": null,
"end_ts_format": null,
"data_schema": [
{
"HR": "float",
"temp": "float"
}
],
"start_data_schema": null,
"end_data_schema": null,
"must_have": []
},
{
"input_df": "./sample_data/raw//labs.csv",
"type": "event",
"event_type": "LAB",
"subject_id_col": "MRN",
"ts_col": "timestamp",
"start_ts_col": null,
"end_ts_col": null,
"ts_format": "%H:%M:%S-%Y-%m-%d",
"start_ts_format": null,
"end_ts_format": null,
"data_schema": [
{
"lab_name": "categorical",
"lab_value": "float"
}
],
"start_data_schema": null,
"end_data_schema": null,
"must_have": []
},
{
"input_df": "./sample_data/raw//medications.csv",
"type": "event",
"event_type": "MEDICATION",
"subject_id_col": "MRN",
"ts_col": "timestamp",
"start_ts_col": null,
"end_ts_col": null,
"ts_format": "%H:%M:%S-%Y-%m-%d",
"start_ts_format": null,
"end_ts_format": null,
"data_schema": [
{
"name": [
"medication",
"categorical"
],
"dose": "float",
"frequency": "categorical",
"duration": "categorical",
"generic_name": "categorical"
}
],
"start_data_schema": null,
"end_data_schema": null,
"must_have": []
}
]
}
This object, stored in JSON format, is an instance of the EventStream.data.config.DatasetSchema object; interested readers can read more about it’s specific formatting requirements there. We can see that this contains much of the same information as was in the initial dataset.yaml config shown above, now with some additional data added as well, such as recognizing that the "lab_name" column should be read in as a categorical type and "lab_value" as a float type.
Beyond the input data schema, the model also writes out the ESGPT’s input overall config object to disk, which stores information about which measurements the pipeline is instructed to extract. That object is stored in config.json:
[13]:
!cat sample_data/processed/sample/config.json | python -m json.tool
{
"measurement_configs": {
"eye_color": {
"name": "eye_color",
"temporality": "static",
"modality": "single_label_classification",
"observation_rate_over_cases": null,
"observation_rate_per_case": null,
"functor": null,
"vocabulary": null,
"values_column": null,
"_measurement_metadata": null,
"modifiers": null
},
"department": {
"name": "department",
"temporality": "dynamic",
"modality": "multi_label_classification",
"observation_rate_over_cases": null,
"observation_rate_per_case": null,
"functor": null,
"vocabulary": null,
"values_column": null,
"_measurement_metadata": null,
"modifiers": null
},
"medication": {
"name": "medication",
"temporality": "dynamic",
"modality": "multi_label_classification",
"observation_rate_over_cases": null,
"observation_rate_per_case": null,
"functor": null,
"vocabulary": null,
"values_column": null,
"_measurement_metadata": null,
"modifiers": [
"dose",
"frequency",
"duration",
"generic_name"
]
},
"HR": {
"name": "HR",
"temporality": "dynamic",
"modality": "univariate_regression",
"observation_rate_over_cases": null,
"observation_rate_per_case": null,
"functor": null,
"vocabulary": null,
"values_column": null,
"_measurement_metadata": null,
"modifiers": null
},
"temp": {
"name": "temp",
"temporality": "dynamic",
"modality": "univariate_regression",
"observation_rate_over_cases": null,
"observation_rate_per_case": null,
"functor": null,
"vocabulary": null,
"values_column": null,
"_measurement_metadata": null,
"modifiers": null
},
"lab_name": {
"name": "lab_name",
"temporality": "dynamic",
"modality": "multivariate_regression",
"observation_rate_over_cases": null,
"observation_rate_per_case": null,
"functor": null,
"vocabulary": null,
"values_column": "lab_value",
"_measurement_metadata": null,
"modifiers": null
},
"age": {
"name": "age",
"temporality": "functional_time_dependent",
"modality": "univariate_regression",
"observation_rate_over_cases": null,
"observation_rate_per_case": null,
"functor": {
"class": "AgeFunctor",
"params": {
"dob_col": "dob"
}
},
"vocabulary": null,
"values_column": null,
"_measurement_metadata": null,
"modifiers": null
}
},
"min_events_per_subject": 3,
"agg_by_time_scale": "1h",
"min_valid_column_observations": 5,
"min_valid_vocab_element_observations": 5,
"min_true_float_frequency": 0.1,
"min_unique_numerical_observations": 20,
"outlier_detector_config": {
"stddev_cutoff": 1.5
},
"center_and_scale": true,
"save_dir": "/home/mmd/Projects/EventStreamGPT/sample_data/processed/sample"
}
Again, much of this information is simply a more verbose re-arrangement of the data specified in dataset.yaml. Notably, no information about the measurements has yet been filled in from the data, though it will eventually be added.
This config structure illustrates a capability of the pipeline outside of the traditional input script format; namely, if one constructs the full config manually, one can pre-specify various measurement specific values (such as vocabulary, normalization parameters, etc.) to be used over what would be inferred from the data.
There is also the full, expanded hydra config stored in hydra_config.yaml, which can help aid in reproducibility.
The final input to the constructor of the EventStream.data.dataset_polars.Dataset class can be seen in the documentation for its base class, EventStream.data.dataset_base.DatasetBase and takeas input:
A
configobject (like that shown in JSON form above.Either the
subjects_df,events_df, anddynamic_measurements_dfdataframes directly or aninput_schemaEventStream.data.config.DatasetSchemaobject which is shown ininput_schema.jsonabove, which is used to construct the three dataframes from source. Currently, the immediate extraction output is not written to disk at all, so we can’t directly inspect thesubjects_df,events_df, anddynamic_measurements_dfthat result from ourinput_schema, but we can see their relative structure from the final, pre-processed dataframes which are written to disk, which we’ll explore next.
Step 2: Data reading and pre-processing¶
After normalizing the input configs, the pipeline next extracts the data from source and performs pre-processing on these dataframes. This pre-processing encompasses several steps, including:
Minimizing data types to minimizing memory/disk footprint.
Splitting data into train, hyperparameter tuning, and held out test sets.
Identifying categorical variable vocabularies.
Converting appropriate numerical variables to categorical.
Fitting numerical outlier detectors and normalizers.
Normalizing numerical data, removing outliers and infrequent vocabulary elements, and writing out processed
subjects_df,events_df, anddynamic_measurements_dfparquet files.
Pre-processed Data Frames¶
After this process is complete, we gain the following three files. Note that we’ll inspect the files manually here, but you can also load the dataset object and inspect them that way, which we’ll do below.
[14]:
!ls --color sample_data/processed/sample/*_df.parquet
sample_data/processed/sample/dynamic_measurements_df.parquet
sample_data/processed/sample/events_df.parquet
sample_data/processed/sample/subjects_df.parquet
[15]:
# We use polars to look at these parquet files:
import polars as pl
pl.Config.set_tbl_cols(7)
display(pl.scan_parquet('sample_data/processed/sample/subjects_df.parquet').head(4).collect())
| subject_id | eye_color | dob |
|---|---|---|
| u32 | cat | datetime[μs] |
| 310243 | "GREEN" | 1981-07-28 00:00:00 |
| 384198 | "BROWN" | 1985-04-15 00:00:00 |
| 520533 | "BROWN" | 1979-04-15 00:00:00 |
| 850710 | "HAZEL" | 1970-08-08 00:00:00 |
The subjects dataframe subjects_df contains subject IDs (which have been re-named and normalized to occupy the minimal possible uint type (here uint8), and contains a categorical eye_color column for our static measurement, but height has been dropped as it wasn’t included in our config.
[16]:
display(pl.scan_parquet('sample_data/processed/sample/events_df.parquet').head(4).collect())
| subject_id | timestamp | event_type | event_id | age | age_is_inlier |
|---|---|---|---|---|---|
| u32 | datetime[μs] | cat | u64 | f64 | bool |
| 15267 | 2010-04-23 04:16:29 | "ADMISSION&VITA… | 9159188870894337796 | 0.440505 | true |
| 15267 | 2010-04-23 05:16:29 | "LAB" | 9567702754158037042 | 0.440531 | true |
| 15267 | 2010-04-23 06:16:29 | "LAB" | 17065118070841774664 | 0.440557 | true |
| 15267 | 2010-04-23 07:16:29 | "VITAL&LAB" | 7840165013239040979 | 0.440583 | true |
The events dataframe events_df contains event IDs, subject IDs, timestamps, event types, and our only functional time dependent measurement, age, in normalized form, alongside an inlier/outlier indicator column. We can also see several other properties:
That these data are sorted, first by
subject_idthen byevent_id(equivalently, bytimestamp).That event timestamps are separated by precisely 1 hour, which was our input aggregation window.
That event types have been aggregated into merged categories during aggregation. E.g., event 1 with event type
VITAL&LABreflects that events of typeVITALandLABhave been merged together. This is to ensure that no subject has two distinct events at the same timestamp.
[17]:
df = pl.scan_parquet('sample_data/processed/sample/dynamic_measurements_df.parquet')
print("Dynamic Measurement Columns:\n * " + '\n * '.join(df.columns))
display(df.head(4).collect())
Dynamic Measurement Columns:
* measurement_id
* department
* HR
* temp
* lab_name
* lab_value
* medication
* dose
* frequency
* duration
* generic_name
* event_id
* HR_is_inlier
* temp_is_inlier
* lab_name_is_inlier
| measurement_id | department | HR | … | HR_is_inlier | temp_is_inlier | lab_name_is_inlier |
|---|---|---|---|---|---|---|
| u32 | cat | f64 | … | bool | bool | bool |
| 0 | "ORTHOPEDIC" | null | … | null | null | null |
| 1 | "CARDIAC" | null | … | null | null | null |
| 2 | "CARDIAC" | null | … | null | null | null |
| 3 | "PULMONARY" | null | … | null | null | null |
The dynamic measurements dataframe dynamic_measurements_df has an ID column, an event_id linking column, and then all our measurements, recorded with missingness.
Fit Measurement Properties¶
In all of these dataframes, we can see the outputs from our learned vocabularies, outlier detector models, and normalizer models. How can we determine what fit parameters were used to make those distinctions? These data are stored in the inferred_measurement_metadata objects. The overall container is stored in inferred_measurement_configs.json, which contains an object linking measurement names to overall configs:
[18]:
!cat sample_data/processed/sample/inferred_measurement_configs.json | python -m json.tool
{
"eye_color": {
"name": "eye_color",
"temporality": "static",
"modality": "single_label_classification",
"observation_rate_over_cases": 1.0,
"observation_rate_per_case": 1.0,
"functor": null,
"vocabulary": {
"vocabulary": [
"UNK",
"BROWN",
"BLUE",
"HAZEL",
"GREEN"
],
"obs_frequencies": [
0.0,
0.5,
0.2625,
0.1625,
0.075
]
},
"values_column": null,
"_measurement_metadata": null,
"modifiers": null
},
"department": {
"name": "department",
"temporality": "dynamic",
"modality": "multi_label_classification",
"observation_rate_over_cases": 0.01233404038023411,
"observation_rate_per_case": 1.0,
"functor": null,
"vocabulary": {
"vocabulary": [
"UNK",
"PULMONARY",
"CARDIAC",
"ORTHOPEDIC"
],
"obs_frequencies": [
0.0,
0.42038216560509556,
0.3503184713375796,
0.22929936305732485
]
},
"values_column": null,
"_measurement_metadata": null,
"modifiers": null
},
"medication": {
"name": "medication",
"temporality": "dynamic",
"modality": "multi_label_classification",
"observation_rate_over_cases": 0.002396103385969047,
"observation_rate_per_case": 1.0,
"functor": null,
"vocabulary": {
"vocabulary": [
"UNK",
"Motrin",
"Benadryl",
"Tylenol",
"Advil",
"motrin"
],
"obs_frequencies": [
0.0,
0.22950819672131148,
0.22950819672131148,
0.21311475409836064,
0.21311475409836064,
0.11475409836065574
]
},
"values_column": null,
"_measurement_metadata": null,
"modifiers": [
"dose",
"frequency",
"duration",
"generic_name"
]
},
"HR": {
"name": "HR",
"temporality": "dynamic",
"modality": "univariate_regression",
"observation_rate_over_cases": 0.7070861811611281,
"observation_rate_per_case": 1.7435698016776846,
"functor": null,
"vocabulary": null,
"values_column": null,
"_measurement_metadata": [
"/home/mmd/Projects/EventStreamGPT/sample_data/processed/sample",
"inferred_measurement_metadata/HR.csv"
],
"modifiers": null
},
"temp": {
"name": "temp",
"temporality": "dynamic",
"modality": "univariate_regression",
"observation_rate_over_cases": 0.7070861811611281,
"observation_rate_per_case": 1.7435698016776846,
"functor": null,
"vocabulary": null,
"values_column": null,
"_measurement_metadata": [
"/home/mmd/Projects/EventStreamGPT/sample_data/processed/sample",
"inferred_measurement_metadata/temp.csv"
],
"modifiers": null
},
"lab_name": {
"name": "lab_name",
"temporality": "dynamic",
"modality": "multivariate_regression",
"observation_rate_over_cases": 0.959462644355409,
"observation_rate_per_case": 1.8555228035699665,
"functor": null,
"vocabulary": {
"vocabulary": [
"UNK",
"SpO2",
"potassium",
"creatinine",
"SOFA__EQ_1",
"SOFA__EQ_2",
"GCS__EQ_1",
"SOFA__EQ_3",
"GCS__EQ_4",
"GCS__EQ_3",
"SOFA__EQ_4",
"GCS__EQ_2",
"GCS__EQ_5",
"GCS__EQ_6",
"GCS__EQ_8",
"GCS__EQ_7",
"GCS__EQ_11",
"GCS__EQ_10",
"GCS__EQ_9",
"GCS__EQ_12",
"GCS__EQ_15",
"GCS__EQ_14",
"GCS__EQ_13"
],
"obs_frequencies": [
0.0,
0.83765417117137,
0.040376850605652756,
0.03490501511373916,
0.028771264038126337,
0.012024799770535931,
0.010061116872228229,
0.005449771639123624,
0.003728791121505637,
0.0033978333296560245,
0.0031551309489663087,
0.0030448116850164374,
0.0025152792180570573,
0.0022505129845773668,
0.002007810603887651,
0.0019857467510976767,
0.001676852812038038,
0.001676852812038038,
0.001654788959248064,
0.001081128786708735,
0.0009708095227588642,
0.0008604902588089932,
0.0007501709948591223
]
},
"values_column": "lab_value",
"_measurement_metadata": [
"/home/mmd/Projects/EventStreamGPT/sample_data/processed/sample",
"inferred_measurement_metadata/lab_name.csv"
],
"modifiers": null
},
"age": {
"name": "age",
"temporality": "functional_time_dependent",
"modality": "univariate_regression",
"observation_rate_over_cases": 1.0,
"observation_rate_per_case": 1.0,
"functor": {
"class": "AgeFunctor",
"params": {
"dob_col": "dob"
}
},
"vocabulary": null,
"values_column": null,
"_measurement_metadata": [
"/home/mmd/Projects/EventStreamGPT/sample_data/processed/sample",
"inferred_measurement_metadata/age.csv"
],
"modifiers": null
}
}
We can see that these objects contain the full vocabularies learned, as well as (for numerical measurements) internal links to further measurement metadata csv files. These csv files contain more detailed statistics for numerical data, such as outlier detector and normalizer models. Let’s inspect two of these, one for the multivariate_regression measurement lab_name and one for the univariate_regression measurement age:
[19]:
display(pl.read_csv('sample_data/processed/sample/inferred_measurement_metadata/lab_name.csv').head(4))
| lab_name | value_type | mean | std | thresh_small | thresh_large |
|---|---|---|---|---|---|
| str | str | f64 | f64 | f64 | f64 |
| "potassium" | "float" | 4.361416 | 0.839229 | -34513.383638 | 35614.997879 |
| "SOFA" | "categorical_in… | null | null | null | null |
| "SpO2" | "integer" | 55.774078 | 10.527999 | -17024.782738 | 17399.716704 |
| "GCS" | "categorical_in… | null | null | null | null |
We can see that the lab_name.csv file contains a dataframe mapping the lab_name (the categorical component of this multivariate regression task) to the inferred value_type (whether the value is a float, integer, categorical_float, or categorical_integer), outlier_model parameters, and normalizer parameters. From this, we can see that the GCS lab test has been interpreted as a categorical_integer, and from the vocabulary in the prior JSON object, we
can see that it takes on values ranging from 1 to 15. In contrast, we can see that the SpO2 lab value is a float a mean of 50.9 (which, to be clear, is a bad real-world SpO2), and has an inferred outlier threshold of approximately \(\pm15000\).
[20]:
display(pl.read_csv('sample_data/processed/sample/inferred_measurement_metadata/age.csv').head(4))
| age | |
|---|---|
| str | str |
| "value_type" | "float" |
| "mean" | "29.83478538470… |
| "std" | "4.394326348123… |
| "thresh_small" | "22.12968667461… |
In contrast to the multivariate_regression measurement file, the univariate age.csv file contains a series representation mapping the three non-categorical-index columns of the prior file to their unique value for age alone. We can see that age is a floating point value, with a mean of \(31.4\pm 4.5\) within the “inlier” range of \(22.9 - 39.4\).
Inspecting the dataset object.¶
We can also look at the same content through the actual object oriented dataset interface, which contains all the above information and more, as loaded through some of the other files in this directory, such as E.pkl which contains other dataset attributes. Let’s do this now.
[21]:
# Imports
from pathlib import Path
from EventStream.data.dataset_polars import Dataset
[22]:
dataset_dir = Path("sample_data/processed/sample")
With the dataset loaded, we can ask about the three dataframes we inspected above…
[23]:
ESD = Dataset.load(dataset_dir)
2024-05-16 13:22:41.022 | INFO | EventStream.data.dataset_base:load:367 - Updating config.save_dir from /home/mmd/Projects/EventStreamGPT/sample_data/processed/sample to sample_data/processed/sample
[24]:
display(ESD.subjects_df.head(3))
display(ESD.events_df.head(3))
display(ESD.dynamic_measurements_df.head(3))
2024-05-16 13:22:41.062 | INFO | EventStream.data.dataset_base:subjects_df:293 - Loading subjects from sample_data/processed/sample/subjects_df.parquet...
| subject_id | eye_color | dob |
|---|---|---|
| u32 | cat | datetime[μs] |
| 310243 | "GREEN" | 1981-07-28 00:00:00 |
| 384198 | "BROWN" | 1985-04-15 00:00:00 |
| 520533 | "BROWN" | 1979-04-15 00:00:00 |
2024-05-16 13:22:41.067 | INFO | EventStream.data.dataset_base:events_df:311 - Loading events from sample_data/processed/sample/events_df.parquet...
| subject_id | timestamp | event_type | event_id | age | age_is_inlier |
|---|---|---|---|---|---|
| u32 | datetime[μs] | cat | u64 | f64 | bool |
| 15267 | 2010-04-23 04:16:29 | "ADMISSION&VITA… | 9159188870894337796 | 0.440505 | true |
| 15267 | 2010-04-23 05:16:29 | "LAB" | 9567702754158037042 | 0.440531 | true |
| 15267 | 2010-04-23 06:16:29 | "LAB" | 17065118070841774664 | 0.440557 | true |
2024-05-16 13:22:41.073 | INFO | EventStream.data.dataset_base:dynamic_measurements_df:330 - Loading dynamic_measurements from sample_data/processed/sample/dynamic_measurements_df.parquet...
| measurement_id | department | HR | … | HR_is_inlier | temp_is_inlier | lab_name_is_inlier |
|---|---|---|---|---|---|---|
| u32 | cat | f64 | … | bool | bool | bool |
| 0 | "ORTHOPEDIC" | null | … | null | null | null |
| 1 | "CARDIAC" | null | … | null | null | null |
| 2 | "CARDIAC" | null | … | null | null | null |
Or about other properties, such as train-test split membership
[25]:
ESD.split_subjects['tuning']
[25]:
{142258,
234683,
428046,
452247,
681894,
705311,
928262,
1230099,
1268909,
1520408}
or vocabulary indices
[26]:
ESD.unified_vocabulary_idxmap
[26]:
{'event_type': {'VITAL&LAB': 1,
'LAB': 2,
'VITAL': 3,
'ADMISSION&VITAL&LAB': 4,
'ADMISSION&VITAL': 5,
'DISCHARGE': 6,
'DISCHARGE&LAB': 7,
'DISCHARGE&VITAL&LAB': 8,
'VITAL&LAB&MEDICATION': 9,
'DISCHARGE&VITAL': 10,
'LAB&MEDICATION': 11,
'MEDICATION': 12,
'VITAL&MEDICATION': 13,
'DISCHARGE&MEDICATION': 14},
'HR': {'HR': 15},
'age': {'age': 16},
'department': {'UNK': 17, 'PULMONARY': 18, 'CARDIAC': 19, 'ORTHOPEDIC': 20},
'eye_color': {'UNK': 21, 'BROWN': 22, 'BLUE': 23, 'HAZEL': 24, 'GREEN': 25},
'lab_name': {'UNK': 26,
'SpO2': 27,
'potassium': 28,
'creatinine': 29,
'SOFA__EQ_1': 30,
'SOFA__EQ_2': 31,
'GCS__EQ_1': 32,
'SOFA__EQ_3': 33,
'GCS__EQ_4': 34,
'GCS__EQ_3': 35,
'SOFA__EQ_4': 36,
'GCS__EQ_2': 37,
'GCS__EQ_5': 38,
'GCS__EQ_6': 39,
'GCS__EQ_8': 40,
'GCS__EQ_7': 41,
'GCS__EQ_11': 42,
'GCS__EQ_10': 43,
'GCS__EQ_9': 44,
'GCS__EQ_12': 45,
'GCS__EQ_15': 46,
'GCS__EQ_14': 47,
'GCS__EQ_13': 48},
'medication': {'UNK': 49,
'Motrin': 50,
'Benadryl': 51,
'Tylenol': 52,
'Advil': 53,
'motrin': 54},
'temp': {'temp': 55}}
And the inferred measurement metadata:
[27]:
ESD.measurement_configs['age'].measurement_metadata
[27]:
value_type float
mean 29.834785384700055
std 4.394326348123329
thresh_small 22.12968667461664
thresh_large 38.112496685358565
Name: age, dtype: object
… or many other properties. Check out the documentation for EventStream.data.dataset_base.DatasetBase for full details.
Moving Datasets¶
Given the various relative files stored in the dataset folder, it’s worth double checking that we can natively move and reload the dataset to different locations in the filepath.
[28]:
!cp sample_data/processed/sample/ sample_data/processed/sample_2 -r
[29]:
ESD_2 = Dataset.load(Path("sample_data/processed/sample_2"))
print(
f"ESD_2 has stored save_dir {ESD_2.config.save_dir}, with dataframes stored at\n"
f" * {ESD_2.subjects_fp(ESD_2.config.save_dir)}\n"
f" * {ESD_2.events_fp(ESD_2.config.save_dir)}\n"
f" * {ESD_2.dynamic_measurements_fp(ESD_2.config.save_dir)}\n"
"\n"
f"Measurement metadata relative filepaths are now similarly updated:\n"
f" * (age): {ESD_2.measurement_configs['age']._measurement_metadata}\n"
"...\n"
"Displaying data:"
)
display(ESD_2.subjects_df.head(2))
display(ESD_2.measurement_configs['age'].measurement_metadata)
2024-05-16 13:22:41.248 | INFO | EventStream.data.dataset_base:load:367 - Updating config.save_dir from /home/mmd/Projects/EventStreamGPT/sample_data/processed/sample to sample_data/processed/sample_2
2024-05-16 13:22:41.268 | INFO | EventStream.data.dataset_base:subjects_df:293 - Loading subjects from sample_data/processed/sample_2/subjects_df.parquet...
ESD_2 has stored save_dir sample_data/processed/sample_2, with dataframes stored at
* sample_data/processed/sample_2/subjects_df.parquet
* sample_data/processed/sample_2/events_df.parquet
* sample_data/processed/sample_2/dynamic_measurements_df.parquet
Measurement metadata relative filepaths are now similarly updated:
* (age): [PosixPath('sample_data/processed/sample_2'), 'inferred_measurement_metadata/age.csv']
...
Displaying data:
| subject_id | eye_color | dob |
|---|---|---|
| u32 | cat | datetime[μs] |
| 310243 | "GREEN" | 1981-07-28 00:00:00 |
| 384198 | "BROWN" | 1985-04-15 00:00:00 |
value_type float
mean 29.834785384700055
std 4.394326348123329
thresh_small 22.12968667461664
thresh_large 38.112496685358565
Name: age, dtype: object
Step 3: Producing DL-friendly Dataframes¶
After the dataset pre-processing is done, the data then needs to be re-formatted to produce the deep-learning friendly data representations. These files live in the DL_reps subfolder:
[30]:
!ls --color sample_data/processed/sample/DL_reps/
held_out train tuning
What do these datasets contain? Rather than the former arrangement of data across three dataframes, here each row corresponds to all data for a given subject, arranged for maximal sparsity and rapid access to temporal data arranged longitudinally. As such, these dataframes have nested columns containing timepoints, indices, and values for the associated subjects.
[31]:
df = pl.scan_parquet('sample_data/processed/sample/DL_reps/tuning/*.parquet')
print("DL Dataframe Columns:\n * " + '\n * '.join(df.columns))
display(df.head(4).collect())
DL Dataframe Columns:
* subject_id
* static_measurement_indices
* static_indices
* start_time
* time
* time_delta
* dynamic_measurement_indices
* dynamic_indices
* dynamic_values
| subject_id | static_measurement_indices | static_indices | … | dynamic_measurement_indices | dynamic_indices | dynamic_values |
|---|---|---|---|---|---|---|
| u32 | list[u8] | list[u8] | … | list[list[u8]] | list[list[u8]] | list[list[f64]] |
| 142258 | [5] | [24] | … | [[1, 3, … 8], [1, 3, … 8], … [1, 3, … 6]] | [[4, 16, … 55], [1, 16, … 55], … [7, 16, … 27]] | [[null, -1.153556, … -0.422736], [null, -1.15353, … -0.526648], … [null, -1.150025, … -0.54845]] |
| 234683 | [5] | [22] | … | [[1, 3, … 8], [1, 3, 6], … [1, 3, 4]] | [[4, 16, … 55], [2, 16, 27], … [6, 16, 19]] | [[null, 1.639285, … -1.46188], [null, 1.639311, 3.535897], … [null, 1.850859, null]] |
| 428046 | [5] | [22] | … | [[1, 3, … 8], [1, 3, … 8], … [1, 3, … 8]] | [[5, 16, … 55], [1, 16, … 55], … [8, 16, … 55]] | [[null, -0.039543, … 0.668365], [null, -0.039517, … 0.824238], … [null, 0.074941, … -0.630565]] |
| 452247 | [5] | [23] | … | [[1, 3, … 8], [1, 3, … 8], … [1, 3, … 8]] | [[5, 16, … 55], [1, 16, … 55], … [8, 16, … 55]] | [[null, 1.744859, … 1.187937], [null, 1.744885, … 1.13598], … [null, 1.786628, … NaN]] |
In addition to these deep-learning datasets, the pipeline also outputs information about the overall vocabulary of the dataset, into the vocabulary_config.json file:
[32]:
!cat sample_data/processed/sample/vocabulary_config.json | python -m json.tool
{
"vocab_sizes_by_measurement": {
"event_type": 14,
"eye_color": 5,
"department": 4,
"medication": 6,
"lab_name": 23
},
"vocab_offsets_by_measurement": {
"event_type": 1,
"HR": 15,
"age": 16,
"department": 17,
"eye_color": 21,
"lab_name": 26,
"medication": 49,
"temp": 55
},
"measurements_idxmap": {
"event_type": 1,
"HR": 2,
"age": 3,
"department": 4,
"eye_color": 5,
"lab_name": 6,
"medication": 7,
"temp": 8
},
"measurements_per_generative_mode": {
"single_label_classification": [
"event_type"
],
"multi_label_classification": [
"department",
"medication",
"lab_name"
],
"univariate_regression": [
"HR",
"temp"
],
"multivariate_regression": [
"lab_name"
]
},
"event_types_idxmap": {
"VITAL&LAB": 1,
"LAB": 2,
"VITAL": 3,
"ADMISSION&VITAL&LAB": 4,
"ADMISSION&VITAL": 5,
"DISCHARGE": 6,
"DISCHARGE&LAB": 7,
"DISCHARGE&VITAL&LAB": 8,
"VITAL&LAB&MEDICATION": 9,
"DISCHARGE&VITAL": 10,
"LAB&MEDICATION": 11,
"MEDICATION": 12,
"VITAL&MEDICATION": 13,
"DISCHARGE&MEDICATION": 14
}
}
In addition, we also produce nested ragged tensor views of the data, for efficient use in deep learning processes with pytorch:
[33]:
from nested_ragged_tensors.ragged_numpy import JointNestedRaggedTensorDict
[34]:
%%time
J = JointNestedRaggedTensorDict.load('sample_data/processed/sample/NRT_reps/tuning/0.pt')
print(J[0][2:5].to_dense())
{'time_delta': array([60., 60., 60.], dtype=float32), 'dim1/mask': array([[ True, True, True, True, True, True, True, True, True,
True, True, False, False],
[ True, True, True, True, True, True, True, False, False,
False, False, False, False],
[ True, True, True, True, True, True, True, True, True,
True, True, True, True]]), 'dynamic_measurement_indices': array([[1, 3, 2, 6, 6, 6, 6, 6, 6, 6, 8, 0, 0],
[1, 3, 2, 2, 6, 8, 8, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 2, 2, 2, 6, 6, 6, 8, 8, 8, 8]], dtype=uint8), 'dynamic_values': array([[ nan, -1.1535041 , -0.02961701, 3.5358973 , 3.7258668 ,
3.630882 , 3.8208516 , 3.4409125 , 3.630882 , 3.9158366 ,
-0.31882283, 0. , 0. ],
[ nan, -1.1534781 , 0.16873288, 0.13854901, 3.7258668 ,
-0.26686248, -0.37077925, 0. , 0. , 0. ,
0. , 0. , 0. ],
[ nan, -1.1534522 , 0.18598042, 0.16010877, 0.01134657,
0.08033773, 3.8208516 , 3.630882 , 3.630882 , -0.5786088 ,
-0.21490607, -0.31882283, -0.42273566]], dtype=float32), 'dynamic_indices': array([[ 1, 16, 15, 27, 27, 27, 27, 27, 27, 27, 55, 0, 0],
[ 1, 16, 15, 15, 27, 55, 55, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 15, 15, 15, 27, 27, 27, 55, 55, 55, 55]], dtype=uint8)}
CPU times: user 32.2 ms, sys: 133 µs, total: 32.4 ms
Wall time: 31.6 ms
These `JointNestedRaggedTensorDict <https://github.com/mmcdermott/nested_ragged_tensors/blob/main/src/nested_ragged_tensors/ragged_numpy.py#L56>`__ objects can also be loaded efficiently in slices:
[35]:
%%time
J = JointNestedRaggedTensorDict.load_slice('sample_data/processed/sample/NRT_reps/tuning/0.pt', 0)
print(J[2:5].to_dense())
{'time_delta': array([60., 60., 60.], dtype=float32), 'dim1/mask': array([[ True, True, True, True, True, True, True, True, True,
True, True, False, False],
[ True, True, True, True, True, True, True, False, False,
False, False, False, False],
[ True, True, True, True, True, True, True, True, True,
True, True, True, True]]), 'dynamic_measurement_indices': array([[1, 3, 2, 6, 6, 6, 6, 6, 6, 6, 8, 0, 0],
[1, 3, 2, 2, 6, 8, 8, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 2, 2, 2, 6, 6, 6, 8, 8, 8, 8]], dtype=uint8), 'dynamic_values': array([[ nan, -1.1535041 , -0.02961701, 3.5358973 , 3.7258668 ,
3.630882 , 3.8208516 , 3.4409125 , 3.630882 , 3.9158366 ,
-0.31882283, 0. , 0. ],
[ nan, -1.1534781 , 0.16873288, 0.13854901, 3.7258668 ,
-0.26686248, -0.37077925, 0. , 0. , 0. ,
0. , 0. , 0. ],
[ nan, -1.1534522 , 0.18598042, 0.16010877, 0.01134657,
0.08033773, 3.8208516 , 3.630882 , 3.630882 , -0.5786088 ,
-0.21490607, -0.31882283, -0.42273566]], dtype=float32), 'dynamic_indices': array([[ 1, 16, 15, 27, 27, 27, 27, 27, 27, 27, 55, 0, 0],
[ 1, 16, 15, 15, 27, 55, 55, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 15, 15, 15, 27, 27, 27, 55, 55, 55, 55]], dtype=uint8)}
CPU times: user 4.04 ms, sys: 16 µs, total: 4.05 ms
Wall time: 4.03 ms
Interacting with DL DataFrames: The Pytorch Dataset¶
How can we best interact with these DL dataframe representations? We can do so through the provided EventStream.data.pytorch_dataset.PytorchDataset class. To create this class, we need to specify a pytorch dataset config object, which contains both (1) a pointer to the directory in which the overall dataset is saved (here processed/sample) and (2) other, pytorch dataset specific parameters such as the max sequence length.
For now, let’s build a pytorch dataset with a maximum sequence length of 8, to keep things nice and easily inspectable. We’ll keep other parameters at their defaults. When you construct a pytorch dataset, you pass in both the config object and a split ('train', 'tuning', or 'held_out'). We’ll pull up the train split for now.
[36]:
from EventStream.data.config import PytorchDatasetConfig
from EventStream.data.types import PytorchBatch
from EventStream.data.pytorch_dataset import PytorchDataset
[37]:
%%time
pyd_config = PytorchDatasetConfig(
save_dir=ESD.config.save_dir,
max_seq_len=8,
)
pyd = PytorchDataset(config=pyd_config, split='train')
2024-05-16 13:22:41.922 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:41.924 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:41.925 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:41.938 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:22:41.975 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 2 events
2024-05-16 13:22:41.976 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 2) from 80 to 80 rows and 80 to 80 subjects.
CPU times: user 54.2 ms, sys: 7.34 ms, total: 61.5 ms
Wall time: 57.7 ms
We don’t print out any of its data here as it looks very large. But what we can print out is what happens when you call the pytorch built-in __getitem__ function for a given index:
[38]:
pyd[0]
[38]:
{'static_indices': [22],
'static_measurement_indices': [5],
'dynamic': JointNestedRaggedTensorDict({'dim0/time_delta': array([60., 60., 60., 60., 60., 60., 60., 60.], dtype=float32), 'dim1/lengths': array([3, 4, 3, 6, 3, 3, 5, 3]), 'dim1/dynamic_measurement_indices': [array([1, 3, 6], dtype=uint8), array([1, 3, 6, 6], dtype=uint8), array([1, 3, 6], dtype=uint8), array([1, 3, 2, 6, 6, 8], dtype=uint8), array([1, 3, 6], dtype=uint8), array([1, 3, 6], dtype=uint8), array([1, 3, 2, 6, 8], dtype=uint8), array([1, 3, 6], dtype=uint8)], 'dim1/dynamic_values': [array([ nan, 0.58424604, 1.5711842 ], dtype=float32), array([ nan, 0.584272 , -0.5484497, -0.4534649], dtype=float32), array([ nan, 0.58429796, -0.5484497 ], dtype=float32), array([ nan, 0.58432394, -0.07273653, nan, -0.5484497 ,
-1.1501372 ], dtype=float32), array([ nan, 0.5843499, -0.4534649], dtype=float32), array([ nan, 0.58437586, -0.5484497 ], dtype=float32), array([ nan, 0.5844018 , -0.04255283, -0.5484497 , -1.2020936 ],
dtype=float32), array([ nan, 0.5844278, -0.5484497], dtype=float32)], 'dim1/dynamic_indices': [array([ 2, 16, 28], dtype=uint8), array([ 2, 16, 27, 27], dtype=uint8), array([ 2, 16, 27], dtype=uint8), array([ 1, 16, 15, 37, 27, 55], dtype=uint8), array([ 2, 16, 27], dtype=uint8), array([ 2, 16, 27], dtype=uint8), array([ 1, 16, 15, 27, 55], dtype=uint8), array([ 2, 16, 27], dtype=uint8)], 'dim1/bounds': array([ 3, 7, 10, 16, 19, 22, 27, 30])}, schema={'dim1/time_delta': dtype('float32'), 'dim2/dynamic_indices': dtype('uint8'), 'dim2/dynamic_measurement_indices': dtype('uint8'), 'dim2/dynamic_values': dtype('float32')}, pre_raggedified=True)}
We can see this returns a dictionary linking names not to tensors, but to lists or lists of lists. This is non-standard for pytorch datasets, as it means the default collate function for dataloaders won’t work for us. Luckily, we provide a built-in custom collate function that can be used via pyd.collate:
[39]:
print(f"`pyd.collate` docstring:\n{pyd.collate.__doc__}")
`pyd.collate` docstring:
Combines the ragged dictionaries produced by `__getitem__` into a tensorized batch.
This function handles conversion of arrays to tensors and padding of elements within the batch across
static data elements, sequence events, and dynamic data elements.
Args:
batch: A list of `__getitem__` format output dictionaries.
Returns:
A fully collated, tensorized, and padded batch.
Producing Batches¶
Now let’s see how the pytorch dataset turns these odd __getitem__ representations into batches for deep-learning, via the provided pyd.collate function:
[40]:
%%time
batch = pyd.collate([pyd[i] for i in range(4)])
CPU times: user 13.5 ms, sys: 535 µs, total: 14 ms
Wall time: 34.6 ms
[41]:
batch
[41]:
PytorchBatch(event_mask=tensor([[True, True, True, True, True, True, True, True],
[True, True, True, True, True, True, True, True],
[True, True, True, True, True, True, True, True],
[True, True, True, True, True, True, True, True]]), time_delta=tensor([[ 60., 60., 60., 60., 60., 60., 60., 60.],
[ 60., 60., 60., 60., 60., 60., 60., 60.],
[ 60., 60., 60., 60., 60., 60., 60., 60.],
[ 60., 60., 60., 60., 120., 60., 120., 60.]]), time=None, static_indices=tensor([[22],
[22],
[22],
[23]]), static_measurement_indices=tensor([[5],
[5],
[5],
[5]]), dynamic_indices=tensor([[[ 1, 16, 15, 15, 15, 27, 27, 32, 27, 55, 55, 55, 0],
[ 1, 16, 15, 27, 55, 0, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 15, 15, 29, 33, 27, 55, 55, 55, 0, 0],
[ 1, 16, 15, 15, 15, 15, 27, 27, 27, 55, 55, 55, 55],
[ 1, 16, 15, 27, 27, 27, 27, 55, 0, 0, 0, 0, 0],
[ 1, 16, 15, 15, 28, 27, 55, 55, 0, 0, 0, 0, 0],
[ 1, 16, 15, 27, 27, 55, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 15, 15, 27, 27, 27, 55, 55, 55, 0, 0]],
[[ 1, 16, 15, 15, 27, 55, 55, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 15, 15, 28, 27, 27, 27, 55, 55, 55, 0],
[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 27, 27, 55, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 27, 55, 0, 0, 0, 0, 0, 0, 0, 0]],
[[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 32, 27, 55, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 29, 27, 27, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 27, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 15, 15, 27, 27, 55, 55, 55, 0, 0, 0],
[ 1, 16, 15, 27, 55, 0, 0, 0, 0, 0, 0, 0, 0]],
[[ 1, 16, 15, 27, 55, 0, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 15, 27, 55, 55, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 27, 27, 55, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 27, 55, 0, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 27, 55, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 1, 16, 15, 27, 55, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2, 16, 27, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]]), dynamic_measurement_indices=tensor([[[1, 3, 2, 2, 2, 6, 6, 6, 6, 8, 8, 8, 0],
[1, 3, 2, 6, 8, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 2, 2, 6, 6, 6, 8, 8, 8, 0, 0],
[1, 3, 2, 2, 2, 2, 6, 6, 6, 8, 8, 8, 8],
[1, 3, 2, 6, 6, 6, 6, 8, 0, 0, 0, 0, 0],
[1, 3, 2, 2, 6, 6, 8, 8, 0, 0, 0, 0, 0],
[1, 3, 2, 6, 6, 8, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 2, 2, 6, 6, 6, 8, 8, 8, 0, 0]],
[[1, 3, 2, 2, 6, 8, 8, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 2, 2, 6, 6, 6, 6, 8, 8, 8, 0],
[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 6, 6, 8, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 6, 8, 0, 0, 0, 0, 0, 0, 0, 0]],
[[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 6, 6, 8, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 6, 6, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 2, 2, 6, 6, 8, 8, 8, 0, 0, 0],
[1, 3, 2, 6, 8, 0, 0, 0, 0, 0, 0, 0, 0]],
[[1, 3, 2, 6, 8, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 2, 6, 8, 8, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 6, 6, 8, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 6, 8, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 6, 8, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 2, 6, 8, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]]), dynamic_values=tensor([[[ 0.0000, 0.5809, -0.0555, 0.1472, -0.0339, -0.5484, -0.5484,
0.0000, -0.5484, -0.8904, -0.7864, -0.8384, 0.0000],
[ 0.0000, 0.5809, 0.1644, -0.5484, -0.9423, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.5810, 0.2011, 0.3649, 0.2981, -1.1520, 0.0000,
-0.5484, -0.7345, -0.9423, -0.7864, 0.0000, 0.0000],
[ 0.0000, 0.5810, 0.2959, 0.2377, 0.4145, 0.1342, -0.4535,
-0.5484, -0.5484, -0.8384, -0.8904, -0.9423, -0.7345],
[ 0.0000, 0.5810, 0.4900, -0.3585, -0.4535, -0.5484, -0.3585,
-1.0462, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.5811, 0.4555, 0.3347, 1.5831, -0.2635, -1.0982,
-0.9423, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.5811, 0.5374, -0.1685, -0.1685, -0.9423, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.5811, 0.4835, 0.3606, 0.6064, -0.5484, -0.2635,
-0.3585, -0.5786, -0.3708, -0.7345, 0.0000, 0.0000]],
[[ 0.0000, 1.0901, 0.0000, 0.0000, -0.5484, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 1.0901, -1.8018, -1.7889, 0.0000, -0.6690, -0.4535,
-0.5484, -0.5484, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 1.0902, -0.5484, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 1.0902, -0.5484, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 1.0902, 0.0000, -0.5484, -0.5484, 2.0193, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 1.0902, -0.5484, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 1.0903, -0.5484, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 1.0903, 0.0000, -0.5484, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[ 0.0000, 0.0000, 1.3512, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 1.4462, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, -0.4500, 0.0000, 1.4462, -0.9943, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, -1.4394, 1.5412, 1.4462, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 1.3512, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.9713, 1.1613, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, -0.5406, -0.7368, -0.5578, 0.8763, 0.9713,
-0.8904, -0.7864, -1.0462, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, -0.8252, 0.6864, -0.8384, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[ 0.0000, -0.0588, 0.0000, -0.5484, 0.4605, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.0588, 0.0000, 0.0000, -0.5484, 0.4086, 0.4605,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.0588, 0.0000, -0.4535, -0.4535, 0.3566, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.0588, 0.0000, -0.3585, 0.5125, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.0587, 0.0000, -0.5484, 0.4605, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.0587, -0.4535, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.0587, 0.0000, -0.5484, 0.6164, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.0586, -0.4535, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]), dynamic_values_mask=tensor([[[False, True, True, True, True, True, True, False, True, True,
True, True, False],
[False, True, True, True, True, False, False, False, False, False,
False, False, False],
[False, True, True, True, True, True, False, True, True, True,
True, False, False],
[False, True, True, True, True, True, True, True, True, True,
True, True, True],
[False, True, True, True, True, True, True, True, False, False,
False, False, False],
[False, True, True, True, True, True, True, True, False, False,
False, False, False],
[False, True, True, True, True, True, False, False, False, False,
False, False, False],
[False, True, True, True, True, True, True, True, True, True,
True, False, False]],
[[False, True, False, False, True, False, False, False, False, False,
False, False, False],
[False, True, True, True, False, True, True, True, True, False,
False, False, False],
[False, True, True, False, False, False, False, False, False, False,
False, False, False],
[False, True, True, False, False, False, False, False, False, False,
False, False, False],
[False, True, False, True, True, True, False, False, False, False,
False, False, False],
[False, True, True, False, False, False, False, False, False, False,
False, False, False],
[False, True, True, False, False, False, False, False, False, False,
False, False, False],
[False, True, False, True, False, False, False, False, False, False,
False, False, False]],
[[False, False, True, False, False, False, False, False, False, False,
False, False, False],
[False, False, True, False, False, False, False, False, False, False,
False, False, False],
[False, False, True, False, True, True, False, False, False, False,
False, False, False],
[False, False, True, True, True, False, False, False, False, False,
False, False, False],
[False, False, True, False, False, False, False, False, False, False,
False, False, False],
[False, False, True, True, False, False, False, False, False, False,
False, False, False],
[False, False, True, True, True, True, True, True, True, True,
False, False, False],
[False, False, True, True, True, False, False, False, False, False,
False, False, False]],
[[False, True, False, True, True, False, False, False, False, False,
False, False, False],
[False, True, False, False, True, True, True, False, False, False,
False, False, False],
[False, True, False, True, True, True, False, False, False, False,
False, False, False],
[False, True, False, True, True, False, False, False, False, False,
False, False, False],
[False, True, False, True, True, False, False, False, False, False,
False, False, False],
[False, True, True, False, False, False, False, False, False, False,
False, False, False],
[False, True, False, True, True, False, False, False, False, False,
False, False, False],
[False, True, True, False, False, False, False, False, False, False,
False, False, False]]]), start_time=None, start_idx=None, end_idx=None, subject_id=None, stream_labels=None)
Firstly, we can see that unlike instantiating the pytorch dataset, batch creation and data retrieval is very fast, which is good. Secondly, we can see that the PyTorch Batch object looks similar to the __getitem__ output except for:
It is an object itself, rather than a plain-old-dictionary (thought it is functionally much like a dictionary).
It contains padded tensors, rather than ragged lists of lists.
Fact 2 is the entire reason we provide a specialized collate function; to handle the nested padding and concatenation for you so that you don’t need to either have massively over-padded batches or write that code yourself.
As these batches are objects, what can you do with them? For starters, they have some helpful helper functions:
[42]:
print(
f"This batch has a batch size of `batch.batch_size = {batch.batch_size}`, "
f"a sequence length of `batch.sequence_length = {batch.sequence_length}`, "
f"with events having no more than `batch.n_data_elements = {batch.n_data_elements}` "
"measurements per event, and patients having no more than "
f"`batch.n_static_data_elements = {batch.n_static_data_elements}` static measurements "
f"per patient. The batch is on device `batch.device = {batch.device}`."
)
This batch has a batch size of `batch.batch_size = 4`, a sequence length of `batch.sequence_length = 8`, with events having no more than `batch.n_data_elements = 13` measurements per event, and patients having no more than `batch.n_static_data_elements = 1` static measurements per patient. The batch is on device `batch.device = cpu`.
You can also slice a batch and have it meaningfully slice sub-patients or sub-events in the batch, e.g.,
[43]:
print(batch[:-1].batch_size, batch[:, :-3].sequence_length, batch[:, :, :-3].n_data_elements)
3 5 10
where slice dimensions are patient, then sequence, then data elements.
You can also even repeat patients in a batch, split a batch into a list of chunks, or convert a batch back into the DL representation view of the data (which is used on in select, niche applications related to generation and zero-shot learning). Note that the repeat and split commands only work for batches suitable for generation (meaning including the start time parameter), which our batch here is not.
[44]:
batch.convert_to_DL_DF()
[44]:
| time_delta | static_indices | static_measurement_indices | dynamic_indices | dynamic_measurement_indices | dynamic_values |
|---|---|---|---|---|---|
| list[f64] | list[f64] | list[f64] | list[list[f64]] | list[list[f64]] | list[list[f64]] |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | [[1.0, 16.0, … 55.0], [1.0, 16.0, … 55.0], … [1.0, 16.0, … 55.0]] | [[1.0, 3.0, … 8.0], [1.0, 3.0, … 8.0], … [1.0, 3.0, … 8.0]] | [[null, 0.580923, … -0.838395], [null, 0.580949, … -0.942308], … [null, 0.581105, … -0.734478]] |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | [[1.0, 16.0, … 55.0], [1.0, 16.0, … 55.0], … [1.0, 16.0, … 55.0]] | [[1.0, 3.0, … 8.0], [1.0, 3.0, … 8.0], … [1.0, 3.0, … 8.0]] | [[null, 1.090112, … null], [null, 1.090138, … null], … [null, 1.090293, … null]] |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | [[2.0, 16.0, 27.0], [2.0, 16.0, 27.0], … [1.0, 16.0, … 55.0]] | [[1.0, 3.0, 6.0], [1.0, 3.0, 6.0], … [1.0, 3.0, … 8.0]] | [[null, null, 1.351247], [null, null, 1.446231], … [null, null, … -0.838395]] |
| [60.0, 60.0, … 60.0] | [23.0] | [5.0] | [[1.0, 16.0, … 55.0], [1.0, 16.0, … 55.0], … [2.0, 16.0, 27.0]] | [[1.0, 3.0, … 8.0], [1.0, 3.0, … 8.0], … [1.0, 3.0, 6.0]] | [[null, -0.058842, … 0.460535], [null, -0.058816, … 0.460535], … [null, -0.058608, -0.453465]] |
Batches have some optional parameters that are only set in select contexts. For example:
Generation Parameters:¶
Batches can have a start time in minutes set for their sampled sub-sequences, which is used during generation but not pre-training. This is controllable via the data config:
[45]:
pyd_with_st_time = PytorchDataset(
config=PytorchDatasetConfig(save_dir=ESD.config.save_dir, do_include_start_time_min=True),
split='tuning'
)
batch_with_st_time = pyd_with_st_time.collate([pyd_with_st_time[i] for i in range(4)])
2024-05-16 13:22:42.091 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:42.093 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:42.093 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:42.106 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:22:42.117 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 2 events
2024-05-16 13:22:42.118 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 2) from 10 to 10 rows and 10 to 10 subjects.
Batches during generation may also pre-compute not just the time deltas, but actually the raw time values as well, but by default this is done during modeling, not in the dataset, so that value is still None by default:
[46]:
batch_with_st_time.time is None
[46]:
True
Lastly, batches can also be right or left padded, sequentially. This is necessary because while right padding is more traditional (so that the real events occur at the lower indices of the tensor on the sequence axis), left padding is necessary during generation so that all sequences are aligned to end at the end of the real-observed sequence elements. To show the difference between these two, we need to make another dataset with a longer sequence length.
[47]:
pyd_right_pad = PytorchDataset(
config=PytorchDatasetConfig(
save_dir=ESD.config.save_dir, do_include_start_time_min=True, seq_padding_side='right',
max_seq_len=10000
),
split='tuning'
)
batch_right_pad = pyd_right_pad.collate([pyd_right_pad[i] for i in range(3)])
2024-05-16 13:22:42.143 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:42.144 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:42.145 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:42.157 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:22:42.167 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 2 events
2024-05-16 13:22:42.168 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 2) from 10 to 10 rows and 10 to 10 subjects.
With this batch (which we make have a very long sequence length so we have some sequences that are for sure padded), we can see that the events are all present on the left, but some are padded on the right.
[48]:
batch_right_pad.event_mask.shape
[48]:
torch.Size([3, 624])
[49]:
batch_right_pad.event_mask[:, :4]
[49]:
tensor([[True, True, True, True],
[True, True, True, True],
[True, True, True, True]])
[50]:
batch_right_pad.event_mask[:, -4:]
[50]:
tensor([[False, False, False, False],
[ True, True, True, True],
[False, False, False, False]])
If we build an analogous batch with seq_padding_side set to left, the behavior will be the opposite.
Note that here we use the enum form of the input for seq_padding_side; however, as (almost) all of the enums we use are StrEnums, they can be equivalently used in enum form or in string form, where the string equivalent value is the lower-cased version of the enum member name.
[51]:
from EventStream.data.config import SeqPaddingSide
pyd_left_pad = PytorchDataset(
config=PytorchDatasetConfig(
save_dir=ESD.config.save_dir, do_include_start_time_min=True, seq_padding_side=SeqPaddingSide.LEFT,
max_seq_len=10000
),
split='tuning'
)
batch_left_pad = pyd_left_pad.collate([pyd_left_pad[i] for i in range(3)])
2024-05-16 13:22:42.207 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:42.209 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:42.210 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:42.226 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:22:42.238 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 2 events
2024-05-16 13:22:42.239 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 2) from 10 to 10 rows and 10 to 10 subjects.
[52]:
batch_left_pad.event_mask.shape
[52]:
torch.Size([3, 624])
[53]:
batch_left_pad.event_mask[:, :4]
[53]:
tensor([[False, False, False, False],
[ True, True, True, True],
[False, False, False, False]])
[54]:
batch_left_pad.event_mask[:, -4:]
[54]:
tensor([[True, True, True, True],
[True, True, True, True],
[True, True, True, True]])
Downstream-task Parameters¶
Batches can also encode downstream task parameters via the stream_labels parameter. We’ll see this in more detail later, when we talk about downstream tasks specifically.
Another task dependent parameter within the PytorchDatasetConfig object is subsequence_sampling_strategy, which dictates whether we choose a sequence of maximal possible length at random from the patient’s record or such that it ends at the end of the valid input window or starts at the start of the valid input window.
Decoding batch or DL representation values¶
To “decode” batch or DL values back to the initial representation, we simply need to convert vocabulary indices to vocabulary elements and use the normalization and outlier detector parameters to convert values back to the appropriate range. Let’s test this by decoding the first 2 events of the first patient’s sampled sub-sequence of the initial batch we created.
[55]:
first_pt_first_2_events = batch[0, :2]
dynamic_indices = first_pt_first_2_events.dynamic_indices
dynamic_meas_indices = first_pt_first_2_events['dynamic_measurement_indices'] # You can use dictionary syntax too
dynamic_vals = first_pt_first_2_events.dynamic_values
dynamic_vals_mask = first_pt_first_2_events.dynamic_values_mask
[56]:
for event_idx in range(2):
print(f"For event {event_idx+1}")
for meas_idx, meas in enumerate(dynamic_meas_indices[event_idx]):
# 0 is padding...
if meas == 0: continue
idx = dynamic_indices[event_idx, meas_idx]
val = dynamic_vals[event_idx, meas_idx]
val_mask = dynamic_vals_mask[event_idx, meas_idx]
meas_vocab_el = {v: k for k, v in ESD.unified_measurements_idxmap.items()}[meas.item()]
vocab_el = {v: k for k, v in ESD.unified_vocabulary_idxmap[meas_vocab_el].items()}[idx.item()]
desc_str = f"{meas_vocab_el}: {vocab_el}"
if val_mask.item():
meas_config = ESD.measurement_configs[meas_vocab_el]
raw_val = val.item()
if meas_config.modality == 'univariate_regression':
mean = float(meas_config.measurement_metadata['mean'])
std = float(meas_config.measurement_metadata['std'])
elif meas_config.modality == 'multivariate_regression':
mean = meas_config.measurement_metadata.loc[vocab_el]['mean'].item()
std = meas_config.measurement_metadata.loc[vocab_el]['std'].item()
else:
raise ValueError(f"meas_config.modality = {meas_config.modality} is invalid!")
desc_str += f" with value {(raw_val * std + mean):.1f}"
print(desc_str)
For event 1
event_type: VITAL&LAB
age: age with value 32.4
HR: HR with value 120.2
HR: HR with value 129.6
HR: HR with value 121.2
lab_name: SpO2 with value 50.0
lab_name: SpO2 with value 50.0
lab_name: GCS__EQ_1
lab_name: SpO2 with value 50.0
temp: temp with value 96.1
temp: temp with value 96.3
temp: temp with value 96.2
For event 2
event_type: VITAL&LAB
age: age with value 32.4
HR: HR with value 130.4
lab_name: SpO2 with value 50.0
temp: temp with value 96.0
Warning: Note that this shows that a single lab name can occur within a single event multiple times! This is non-standard, and can have poor implications on loss weighting if not addressed properly (which it likely is not in the default model architectures distributed with ESGPT).
There is also a method that is useful during generation to convert a batch back into a dataframe like format; note, however, that it is missing appropriate join keys such as subject_id and the paritcular sampled sub-sequence’s indices in the raw data.
[57]:
batch.convert_to_DL_DF()
[57]:
| time_delta | static_indices | static_measurement_indices | dynamic_indices | dynamic_measurement_indices | dynamic_values |
|---|---|---|---|---|---|
| list[f64] | list[f64] | list[f64] | list[list[f64]] | list[list[f64]] | list[list[f64]] |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | [[1.0, 16.0, … 55.0], [1.0, 16.0, … 55.0], … [1.0, 16.0, … 55.0]] | [[1.0, 3.0, … 8.0], [1.0, 3.0, … 8.0], … [1.0, 3.0, … 8.0]] | [[null, 0.580923, … -0.838395], [null, 0.580949, … -0.942308], … [null, 0.581105, … -0.734478]] |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | [[1.0, 16.0, … 55.0], [1.0, 16.0, … 55.0], … [1.0, 16.0, … 55.0]] | [[1.0, 3.0, … 8.0], [1.0, 3.0, … 8.0], … [1.0, 3.0, … 8.0]] | [[null, 1.090112, … null], [null, 1.090138, … null], … [null, 1.090293, … null]] |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | [[2.0, 16.0, 27.0], [2.0, 16.0, 27.0], … [1.0, 16.0, … 55.0]] | [[1.0, 3.0, 6.0], [1.0, 3.0, 6.0], … [1.0, 3.0, … 8.0]] | [[null, null, 1.351247], [null, null, 1.446231], … [null, null, … -0.838395]] |
| [60.0, 60.0, … 60.0] | [23.0] | [5.0] | [[1.0, 16.0, … 55.0], [1.0, 16.0, … 55.0], … [2.0, 16.0, 27.0]] | [[1.0, 3.0, … 8.0], [1.0, 3.0, … 8.0], … [1.0, 3.0, 6.0]] | [[null, -0.058842, … 0.460535], [null, -0.058816, … 0.460535], … [null, -0.058608, -0.453465]] |
We can add some of those control variables back in via additional dataset configuration options:
[58]:
pyd_config_with_metadata = PytorchDatasetConfig(
save_dir=ESD.config.save_dir,
max_seq_len=8,
do_include_start_time_min=True,
do_include_subsequence_indices=True,
do_include_subject_id=True,
)
pyd_with_metadata = PytorchDataset(config=pyd_config_with_metadata, split='train')
batch_with_metadata = pyd_with_metadata.collate([pyd_with_metadata[i] for i in range(4)])
batch_with_metadata.convert_to_DL_DF()
2024-05-16 13:22:42.366 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:42.368 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:42.369 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:42.388 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:22:42.400 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 2 events
2024-05-16 13:22:42.401 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 2) from 80 to 80 rows and 80 to 80 subjects.
[58]:
| time_delta | static_indices | static_measurement_indices | … | start_idx | end_idx | subject_id |
|---|---|---|---|---|---|---|
| list[f64] | list[f64] | list[f64] | … | f64 | f64 | f64 |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | … | 296.0 | 304.0 | 15267.0 |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | … | 28.0 | 36.0 | 42335.0 |
| [60.0, 60.0, … 60.0] | [22.0] | [5.0] | … | 86.0 | 94.0 | 72293.0 |
| [120.0, 60.0, … 120.0] | [23.0] | [5.0] | … | 385.0 | 393.0 | 87570.0 |
Flat Representations¶
ESGPT Also supports producing flat representations of datasets, for use with baseline pipelines. These can be produced by calling the cache_flat_representations method on an ESGPT dataset.
[59]:
ESD.cache_flat_representation(
subjects_per_output_file=5,
feature_inclusion_frequency=None,
window_sizes=['7d', 'FULL'],
do_overwrite=False,
do_update=True,
)
2024-05-16 13:22:42.437 | INFO | EventStream.data.dataset_base:cache_flat_representation:1174 - Caching flat representations
These flat files are stored in the flat_reps subdirectory of the dataset configuration file’s save directory. The structure of these files is as follows:
[60]:
!ls -R --color -lh sample_data/processed/sample/flat_reps
sample_data/processed/sample/flat_reps:
total 16K
drwxrwxr-x 5 mmd mmd 4.0K May 16 13:22 at_ts
drwxrwxr-x 5 mmd mmd 4.0K May 16 13:22 over_history
-rw-rw-r-- 1 mmd mmd 1.1K May 16 13:22 params.json
drwxrwxr-x 5 mmd mmd 4.0K May 16 13:22 static
sample_data/processed/sample/flat_reps/at_ts:
total 12K
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 held_out
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 train
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 tuning
sample_data/processed/sample/flat_reps/at_ts/held_out:
total 252K
-rw-rw-r-- 1 mmd mmd 124K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 126K May 16 13:22 1.parquet
sample_data/processed/sample/flat_reps/at_ts/train:
total 2.1M
-rw-rw-r-- 1 mmd mmd 124K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 120K May 16 13:22 10.parquet
-rw-rw-r-- 1 mmd mmd 141K May 16 13:22 11.parquet
-rw-rw-r-- 1 mmd mmd 109K May 16 13:22 12.parquet
-rw-rw-r-- 1 mmd mmd 116K May 16 13:22 13.parquet
-rw-rw-r-- 1 mmd mmd 100K May 16 13:22 14.parquet
-rw-rw-r-- 1 mmd mmd 124K May 16 13:22 15.parquet
-rw-rw-r-- 1 mmd mmd 149K May 16 13:22 1.parquet
-rw-rw-r-- 1 mmd mmd 136K May 16 13:22 2.parquet
-rw-rw-r-- 1 mmd mmd 142K May 16 13:22 3.parquet
-rw-rw-r-- 1 mmd mmd 126K May 16 13:22 4.parquet
-rw-rw-r-- 1 mmd mmd 134K May 16 13:22 5.parquet
-rw-rw-r-- 1 mmd mmd 130K May 16 13:22 6.parquet
-rw-rw-r-- 1 mmd mmd 163K May 16 13:22 7.parquet
-rw-rw-r-- 1 mmd mmd 133K May 16 13:22 8.parquet
-rw-rw-r-- 1 mmd mmd 129K May 16 13:22 9.parquet
sample_data/processed/sample/flat_reps/at_ts/tuning:
total 240K
-rw-rw-r-- 1 mmd mmd 93K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 144K May 16 13:22 1.parquet
sample_data/processed/sample/flat_reps/over_history:
total 12K
drwxrwxr-x 4 mmd mmd 4.0K May 16 13:22 held_out
drwxrwxr-x 4 mmd mmd 4.0K May 16 13:22 train
drwxrwxr-x 4 mmd mmd 4.0K May 16 13:22 tuning
sample_data/processed/sample/flat_reps/over_history/held_out:
total 8.0K
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 7d
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 FULL
sample_data/processed/sample/flat_reps/over_history/held_out/7d:
total 276K
-rw-rw-r-- 1 mmd mmd 133K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 139K May 16 13:22 1.parquet
sample_data/processed/sample/flat_reps/over_history/held_out/FULL:
total 288K
-rw-rw-r-- 1 mmd mmd 138K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 146K May 16 13:22 1.parquet
sample_data/processed/sample/flat_reps/over_history/train:
total 8.0K
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 7d
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 FULL
sample_data/processed/sample/flat_reps/over_history/train/7d:
total 2.3M
-rw-rw-r-- 1 mmd mmd 133K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 134K May 16 13:22 10.parquet
-rw-rw-r-- 1 mmd mmd 163K May 16 13:22 11.parquet
-rw-rw-r-- 1 mmd mmd 119K May 16 13:22 12.parquet
-rw-rw-r-- 1 mmd mmd 127K May 16 13:22 13.parquet
-rw-rw-r-- 1 mmd mmd 108K May 16 13:22 14.parquet
-rw-rw-r-- 1 mmd mmd 136K May 16 13:22 15.parquet
-rw-rw-r-- 1 mmd mmd 165K May 16 13:22 1.parquet
-rw-rw-r-- 1 mmd mmd 154K May 16 13:22 2.parquet
-rw-rw-r-- 1 mmd mmd 163K May 16 13:22 3.parquet
-rw-rw-r-- 1 mmd mmd 139K May 16 13:22 4.parquet
-rw-rw-r-- 1 mmd mmd 153K May 16 13:22 5.parquet
-rw-rw-r-- 1 mmd mmd 146K May 16 13:22 6.parquet
-rw-rw-r-- 1 mmd mmd 185K May 16 13:22 7.parquet
-rw-rw-r-- 1 mmd mmd 151K May 16 13:22 8.parquet
-rw-rw-r-- 1 mmd mmd 146K May 16 13:22 9.parquet
sample_data/processed/sample/flat_reps/over_history/train/FULL:
total 2.4M
-rw-rw-r-- 1 mmd mmd 135K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 139K May 16 13:22 10.parquet
-rw-rw-r-- 1 mmd mmd 168K May 16 13:22 11.parquet
-rw-rw-r-- 1 mmd mmd 123K May 16 13:22 12.parquet
-rw-rw-r-- 1 mmd mmd 130K May 16 13:22 13.parquet
-rw-rw-r-- 1 mmd mmd 110K May 16 13:22 14.parquet
-rw-rw-r-- 1 mmd mmd 138K May 16 13:22 15.parquet
-rw-rw-r-- 1 mmd mmd 173K May 16 13:22 1.parquet
-rw-rw-r-- 1 mmd mmd 158K May 16 13:22 2.parquet
-rw-rw-r-- 1 mmd mmd 168K May 16 13:22 3.parquet
-rw-rw-r-- 1 mmd mmd 143K May 16 13:22 4.parquet
-rw-rw-r-- 1 mmd mmd 157K May 16 13:22 5.parquet
-rw-rw-r-- 1 mmd mmd 150K May 16 13:22 6.parquet
-rw-rw-r-- 1 mmd mmd 192K May 16 13:22 7.parquet
-rw-rw-r-- 1 mmd mmd 157K May 16 13:22 8.parquet
-rw-rw-r-- 1 mmd mmd 149K May 16 13:22 9.parquet
sample_data/processed/sample/flat_reps/over_history/tuning:
total 8.0K
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 7d
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 FULL
sample_data/processed/sample/flat_reps/over_history/tuning/7d:
total 264K
-rw-rw-r-- 1 mmd mmd 100K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 164K May 16 13:22 1.parquet
sample_data/processed/sample/flat_reps/over_history/tuning/FULL:
total 272K
-rw-rw-r-- 1 mmd mmd 100K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 170K May 16 13:22 1.parquet
sample_data/processed/sample/flat_reps/static:
total 12K
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 held_out
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 train
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 tuning
sample_data/processed/sample/flat_reps/static/held_out:
total 8.0K
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 1.parquet
sample_data/processed/sample/flat_reps/static/train:
total 64K
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 10.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 11.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 12.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 13.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 14.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 15.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 1.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 2.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 3.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 4.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 5.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 6.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 7.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 8.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 9.parquet
sample_data/processed/sample/flat_reps/static/tuning:
total 8.0K
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 2.3K May 16 13:22 1.parquet
[61]:
!du -sh sample_data/processed/sample/flat_reps
8.5M sample_data/processed/sample/flat_reps
[62]:
!du -sh sample_data/processed/sample/flat_reps/*
2.6M sample_data/processed/sample/flat_reps/at_ts
5.8M sample_data/processed/sample/flat_reps/over_history
4.0K sample_data/processed/sample/flat_reps/params.json
96K sample_data/processed/sample/flat_reps/static
We can also load these representations more easily using the EventStream.evaluation.tasks.profile helper:
[63]:
from EventStream.baseline.FT_task_baseline import load_flat_rep
[64]:
%%time
flat_reps = load_flat_rep(ESD, window_sizes=['7d'])
print(f"Dataset has {flat_reps['train'].select(pl.count()).collect().item()} rows and {len(flat_reps['train'].columns)} columns")
display(flat_reps['train'].head().collect())
Dataset has 25458 rows and 173 columns
<timed exec>:2: DeprecationWarning: `pl.count()` is deprecated. Please use `pl.len()` instead.
| subject_id | timestamp | 7d/HR/HR/count | … | static/eye_color/GREEN/present | static/eye_color/HAZEL/present | static/eye_color/UNK/present |
|---|---|---|---|---|---|---|
| u32 | datetime[μs] | u16 | … | bool | bool | bool |
| 42335 | 2010-03-06 05:33:18 | 1 | … | null | null | null |
| 42335 | 2010-03-06 06:33:18 | 1 | … | null | null | null |
| 42335 | 2010-03-06 07:33:18 | 3 | … | null | null | null |
| 42335 | 2010-03-06 08:33:18 | 7 | … | null | null | null |
| 42335 | 2010-03-06 09:33:18 | 8 | … | null | null | null |
CPU times: user 122 ms, sys: 15.3 ms, total: 137 ms
Wall time: 59.9 ms
With this helper, we can also dynamically adjust the columns loaded on the fly:
[65]:
%%time
flat_reps = load_flat_rep(ESD, window_sizes=['FULL'], feature_inclusion_frequency=0.001)
print(f"Dataset has {flat_reps['train'].select(pl.count()).collect().item()} rows and {len(flat_reps['train'].columns)} columns")
display(flat_reps['train'].head().collect())
Dataset has 25458 rows and 155 columns
<timed exec>:2: DeprecationWarning: `pl.count()` is deprecated. Please use `pl.len()` instead.
| subject_id | timestamp | FULL/HR/HR/count | … | static/eye_color/GREEN/present | static/eye_color/HAZEL/present | static/eye_color/UNK/present |
|---|---|---|---|---|---|---|
| u32 | datetime[μs] | u16 | … | bool | bool | bool |
| 1499770 | 2010-04-27 07:38:43 | 1 | … | null | null | null |
| 1499770 | 2010-04-27 08:38:43 | 1 | … | null | null | null |
| 1499770 | 2010-04-27 09:38:43 | 2 | … | null | null | null |
| 1499770 | 2010-04-27 10:38:43 | 4 | … | null | null | null |
| 1499770 | 2010-04-27 11:38:43 | 6 | … | null | null | null |
CPU times: user 132 ms, sys: 12 ms, total: 144 ms
Wall time: 62.8 ms
We can even compute new window sizes as needed to extend the cached historical representation.
[66]:
%%time
flat_reps = load_flat_rep(ESD, window_sizes=['1d', '7d', 'FULL'])
print(f"Dataset has {flat_reps['train'].select(pl.count()).collect().item()} rows and {len(flat_reps['train'].columns)} columns")
display(flat_reps['train'].head().collect())
2024-05-16 13:22:46.322 | INFO | EventStream.data.dataset_base:cache_flat_representation:1174 - Caching flat representations
2024-05-16 13:22:46.324 | INFO | EventStream.data.dataset_base:cache_flat_representation:1211 - Standardizing chunk size to existing record (5).
Dataset has 25458 rows and 505 columns
<timed exec>:2: DeprecationWarning: `pl.count()` is deprecated. Please use `pl.len()` instead.
| subject_id | timestamp | 1d/HR/HR/count | … | static/eye_color/GREEN/present | static/eye_color/HAZEL/present | static/eye_color/UNK/present |
|---|---|---|---|---|---|---|
| u32 | datetime[μs] | u16 | … | bool | bool | bool |
| 1499770 | 2010-04-27 07:38:43 | 1 | … | null | null | null |
| 1499770 | 2010-04-27 08:38:43 | 1 | … | null | null | null |
| 1499770 | 2010-04-27 09:38:43 | 2 | … | null | null | null |
| 1499770 | 2010-04-27 10:38:43 | 4 | … | null | null | null |
| 1499770 | 2010-04-27 11:38:43 | 6 | … | null | null | null |
CPU times: user 1.39 s, sys: 460 ms, total: 1.85 s
Wall time: 1.07 s
Note that if we were to attempt to do this with incompatible parameters (e.g., by using a feature inclusion frequency that differs from that used with the base cache attempt), or if we turn updating off, it would throw an error:
[67]:
try:
flat_reps = load_flat_rep(ESD, window_sizes=['2d'], do_update_if_missing=False)
except FileNotFoundError as e:
print(f"Errored out with error {e}")
Errored out with error Missing files! Needs measurements: False; Needs features: False; Needs windows: True.
We can also load only a subset of subjects at a time, globally, specified through a dictionary of allowed subjects per split.
[68]:
%%time
flat_reps = load_flat_rep(
ESD, window_sizes=['1d', '7d', 'FULL'],
subjects_included={'train': set(sorted(list(ESD.split_subjects['train']))[:3])}
)
print(f"Dataset has {flat_reps['train'].select(pl.count()).collect().item()} rows and {len(flat_reps['train'].columns)} columns")
display(flat_reps['train'].head().collect())
Dataset has 789 rows and 505 columns
<timed exec>:5: DeprecationWarning: `pl.count()` is deprecated. Please use `pl.len()` instead.
| subject_id | timestamp | 1d/HR/HR/count | … | static/eye_color/GREEN/present | static/eye_color/HAZEL/present | static/eye_color/UNK/present |
|---|---|---|---|---|---|---|
| u32 | datetime[μs] | u16 | … | bool | bool | bool |
| 42335 | 2010-03-06 05:33:18 | 1 | … | null | null | null |
| 42335 | 2010-03-06 06:33:18 | 1 | … | null | null | null |
| 42335 | 2010-03-06 07:33:18 | 3 | … | null | null | null |
| 42335 | 2010-03-06 08:33:18 | 7 | … | null | null | null |
| 42335 | 2010-03-06 09:33:18 | 8 | … | null | null | null |
CPU times: user 280 ms, sys: 20.6 ms, total: 300 ms
Wall time: 161 ms
The most powerful utility of this helper function, however, is that we can additionally run this load operation while filtering the data down to just those rows that correspond to records in a task dataframe, thereby greatly reducing the cost to load the data and enabling us to load different features and historical summarization windows for downstream tasks. To illustrate this capability, we first need to show how we can define dataframes for downstream tasks in this model.
Downstream Tasks¶
Now that we’ve explored batches and the default datasets for general sequence modelling, let’s look at downstream tasks more specifically. To use this library for a downstream task, we need a way to limit our dataset to a specific cohort, which in practice means defining a set of valid subject IDs to include and a set of associated valid start and end ranges to use for those subject IDs.
Right now, this is done through a dataframe containing these columns alongside any labels associated with those inputs you wish to enforce.
Let’s build a sample such task dataframe to use with our data. We can do so with the script sample_data/build_sample_task_df.py. For this example, this script just builds a dataframe that has the appropriate schema, but assigns random labels to the selected records, but for real-world task dataframe usage, you can also see the MIMIC-IV tutorial, which includes actual task dataframes.
[69]:
command = """\
PYTHONPATH=$(pwd):$PYTHONPATH ./sample_data/build_sample_task_DF.py \
+dataset_dir=./sample_data/processed/sample"""
command_out = subprocess.run(command, shell=True, capture_output=True)
print(command_out.stdout.decode())
if command_out.returncode == 1:
print("Command Errored!")
print(command_out.stderr.decode())
2024-05-16 13:22:49.470 | INFO | EventStream.data.dataset_base:load:367 - Updating config.save_dir from /home/mmd/Projects/EventStreamGPT/sample_data/processed/sample to sample_data/processed/sample
2024-05-16 13:22:49.478 | INFO | EventStream.data.dataset_base:events_df:311 - Loading events from sample_data/processed/sample/events_df.parquet...
Now, we can inspect these task dataframes to see what format they have. To be read by built-in components of the ESGPT pipeline, task dataframes need to be stored in the task_dfs subdirectory of the dataset’s overall save directory:
[70]:
!ls --color -lh ./sample_data/processed/sample/task_dfs/
total 12K
-rw-rw-r-- 1 mmd mmd 2.7K May 16 13:22 multi_class_classification.parquet
-rw-rw-r-- 1 mmd mmd 2.6K May 16 13:22 single_label_binary_classification.parquet
-rw-rw-r-- 1 mmd mmd 3.0K May 16 13:22 univariate_regression.parquet
[71]:
df = pl.scan_parquet("sample_data/processed/sample/task_dfs/multi_class_classification.parquet")
df.head().collect()
[71]:
| subject_id | end_time | label | start_time |
|---|---|---|---|
| u32 | datetime[μs] | u32 | datetime[μs] |
| 142258 | 2010-01-30 08:59:04 | 1 | null |
| 1569956 | 2010-02-11 20:14:05 | 1 | null |
| 1356169 | 2010-01-19 08:07:21 | 2 | null |
| 615036 | 2010-04-19 11:40:56 | 2 | null |
| 384198 | 2010-02-14 04:16:13 | 0 | null |
We can also load these with an ESGPT utility function:
[72]:
from EventStream.tasks.profile import add_tasks_from
[73]:
tasks = add_tasks_from(ESD.config.save_dir / 'task_dfs')
for task, df in tasks.items():
print(task)
display(df.head(2).collect())
single_label_binary_classification
| subject_id | end_time | label | start_time |
|---|---|---|---|
| u32 | datetime[μs] | bool | datetime[μs] |
| 867495 | 2010-03-16 23:53:27 | true | null |
| 452247 | 2010-04-03 17:50:43 | false | null |
multi_class_classification
| subject_id | end_time | label | start_time |
|---|---|---|---|
| u32 | datetime[μs] | u32 | datetime[μs] |
| 142258 | 2010-01-30 08:59:04 | 1 | null |
| 1569956 | 2010-02-11 20:14:05 | 1 | null |
univariate_regression
| subject_id | end_time | label | start_time |
|---|---|---|---|
| u32 | datetime[μs] | f32 | datetime[μs] |
| 505484 | 2010-10-17 20:25:27 | 0.332814 | null |
| 1230099 | 2010-06-27 23:56:09 | -0.651281 | null |
Using task dataframes to load flat data.¶
To load just a subset of the flat representation files via a task dataframe, we simply pass in the task name to the load function. While, in this synthetic example, it is actually slower, on larger datasets it is considerably faster, and the memory saving is very significant.
[74]:
%%time
flat_reps = load_flat_rep(ESD, window_sizes=['7d'], task_df_name='single_label_binary_classification')
print(f"Dataset has {flat_reps['train'].select(pl.len()).collect().item()} rows and {len(flat_reps['train'].columns)} columns")
display(flat_reps['train'].head().collect())
Dataset has 80 rows and 175 columns
| subject_id | timestamp | label | … | static/eye_color/GREEN/present | static/eye_color/HAZEL/present | static/eye_color/UNK/present |
|---|---|---|---|---|---|---|
| u32 | datetime[μs] | bool | … | bool | bool | bool |
| 1356169 | 2010-03-11 09:07:21 | false | … | null | true | null |
| 1569956 | 2010-02-04 17:14:05 | true | … | null | true | null |
| 759652 | 2010-08-29 23:21:25 | false | … | null | null | null |
| 883221 | 2010-08-14 06:28:40 | true | … | null | null | null |
| 505484 | 2011-01-03 06:25:27 | true | … | null | true | null |
CPU times: user 367 ms, sys: 64 ms, total: 431 ms
Wall time: 300 ms
This process also caches the task filtered subset, so subsequent loads on the same task name will be faster (again, on real data specifically). We can inspect the cached files in the raw file tree as well:
[75]:
!ls -R --color -lh sample_data/processed/sample/flat_reps/task_histories/
sample_data/processed/sample/flat_reps/task_histories/:
total 4.0K
drwxrwxr-x 5 mmd mmd 4.0K May 16 13:22 single_label_binary_classification
sample_data/processed/sample/flat_reps/task_histories/single_label_binary_classification:
total 12K
drwxrwxr-x 3 mmd mmd 4.0K May 16 13:22 held_out
drwxrwxr-x 3 mmd mmd 4.0K May 16 13:22 train
drwxrwxr-x 3 mmd mmd 4.0K May 16 13:22 tuning
sample_data/processed/sample/flat_reps/task_histories/single_label_binary_classification/held_out:
total 4.0K
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 7d
sample_data/processed/sample/flat_reps/task_histories/single_label_binary_classification/held_out/7d:
total 128K
-rw-rw-r-- 1 mmd mmd 63K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 1.parquet
sample_data/processed/sample/flat_reps/task_histories/single_label_binary_classification/train:
total 4.0K
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 7d
sample_data/processed/sample/flat_reps/task_histories/single_label_binary_classification/train/7d:
total 1.0M
-rw-rw-r-- 1 mmd mmd 63K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 10.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 11.parquet
-rw-rw-r-- 1 mmd mmd 63K May 16 13:22 12.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 13.parquet
-rw-rw-r-- 1 mmd mmd 63K May 16 13:22 14.parquet
-rw-rw-r-- 1 mmd mmd 63K May 16 13:22 15.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 1.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 2.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 3.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 4.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 5.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 6.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 7.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 8.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 9.parquet
sample_data/processed/sample/flat_reps/task_histories/single_label_binary_classification/tuning:
total 4.0K
drwxrwxr-x 2 mmd mmd 4.0K May 16 13:22 7d
sample_data/processed/sample/flat_reps/task_histories/single_label_binary_classification/tuning/7d:
total 128K
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 0.parquet
-rw-rw-r-- 1 mmd mmd 64K May 16 13:22 1.parquet
We can, of course, turn off caching if we wish:
[76]:
%%time
flat_reps = load_flat_rep(
ESD, window_sizes=['FULL', '1d'], task_df_name='multi_class_classification', do_cache_filtered_task=False
)
print(f"Dataset has {flat_reps['train'].select(pl.len()).collect().item()} rows and {len(flat_reps['train'].columns)} columns")
display(flat_reps['train'].head().collect())
Dataset has 80 rows and 341 columns
| subject_id | timestamp | label | … | static/eye_color/GREEN/present | static/eye_color/HAZEL/present | static/eye_color/UNK/present |
|---|---|---|---|---|---|---|
| u32 | datetime[μs] | u32 | … | bool | bool | bool |
| 1569956 | 2010-02-11 20:14:05 | 1 | … | null | true | null |
| 1356169 | 2010-01-19 08:07:21 | 2 | … | null | true | null |
| 384198 | 2010-02-14 04:16:13 | 0 | … | null | null | null |
| 759652 | 2010-02-27 01:21:25 | 0 | … | null | null | null |
| 883221 | 2010-08-14 19:28:40 | 0 | … | null | null | null |
CPU times: user 269 ms, sys: 72.9 ms, total: 342 ms
Wall time: 172 ms
[77]:
!ls --color -lh sample_data/processed/sample/flat_reps/task_histories/
total 4.0K
drwxrwxr-x 5 mmd mmd 4.0K May 16 13:22 single_label_binary_classification
Again, we can also restrict subjects:
[78]:
%%time
flat_reps = load_flat_rep(
ESD, window_sizes=['FULL', '1d'], task_df_name='single_label_binary_classification',
subjects_included={'train': set(sorted(list(ESD.split_subjects['train']))[:3])}
)
print(f"Dataset has {flat_reps['train'].select(pl.len()).collect().item()} rows and {len(flat_reps['train'].columns)} columns")
display(flat_reps['train'].head().collect())
Dataset has 3 rows and 341 columns
| subject_id | timestamp | label | … | static/eye_color/GREEN/present | static/eye_color/HAZEL/present | static/eye_color/UNK/present |
|---|---|---|---|---|---|---|
| u32 | datetime[μs] | bool | … | bool | bool | bool |
| 42335 | 2010-03-09 11:33:18 | true | … | null | null | null |
| 72293 | 2010-01-18 15:34:43 | true | … | null | null | null |
| 15267 | 2010-10-13 10:16:29 | true | … | null | null | null |
CPU times: user 656 ms, sys: 113 ms, total: 768 ms
Wall time: 564 ms
Using task dataframes to load PyTorch Datasets¶
You can also condition a pytorch dataset via a task dataframe. To do so, simply pass the task name to the PytorchDatasetConfig.
[79]:
%%time
pyd_config = PytorchDatasetConfig(
save_dir=ESD.config.save_dir,
max_seq_len=8,
task_df_name="single_label_binary_classification"
)
pyd_single_label_binary = PytorchDataset(config=pyd_config, split='train')
print(len(pyd_single_label_binary))
pyd_config = PytorchDatasetConfig(
save_dir=ESD.config.save_dir,
max_seq_len=8,
task_df_name="multi_class_classification"
)
pyd_multi_class = PytorchDataset(config=pyd_config, split='train')
print(len(pyd_multi_class))
2024-05-16 13:22:51.469 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:51.471 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:51.471 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:51.483 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:22:51.494 | INFO | EventStream.data.pytorch_dataset:read_patient_descriptors:233 - Reading task constraints for single_label_binary_classification from sample_data/processed/sample/task_dfs/single_label_binary_classification.parquet
2024-05-16 13:22:51.526 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 2 events
2024-05-16 13:22:51.529 | WARNING | EventStream.data.pytorch_dataset:filter_to_min_seq_len:337 - Filtering task single_label_binary_classification to min_seq_len 2. This may result in incomparable model results against runs with different constraints!
2024-05-16 13:22:51.530 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 2) from 100 to 79 rows and 100 to 79 subjects.
2024-05-16 13:22:51.532 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:51.533 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:51.534 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:51.550 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
79
2024-05-16 13:22:51.562 | INFO | EventStream.data.pytorch_dataset:read_patient_descriptors:233 - Reading task constraints for multi_class_classification from sample_data/processed/sample/task_dfs/multi_class_classification.parquet
2024-05-16 13:22:51.606 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 2 events
2024-05-16 13:22:51.607 | WARNING | EventStream.data.pytorch_dataset:filter_to_min_seq_len:337 - Filtering task multi_class_classification to min_seq_len 2. This may result in incomparable model results against runs with different constraints!
2024-05-16 13:22:51.608 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 2) from 100 to 80 rows and 100 to 80 subjects.
80
CPU times: user 116 ms, sys: 58.2 ms, total: 174 ms
Wall time: 145 ms
In this cached directory, parameters about the task are written to the task_info.json file, including the task’s vocabulary and type:
[80]:
!cat sample_data/processed/sample/task_dfs/single_label_binary_classification_info.json | python -m json.tool
{
"tasks": [
"label"
],
"vocabs": {
"label": [
false,
true
]
},
"types": {
"label": "binary_classification"
}
}
[81]:
!cat sample_data/processed/sample/task_dfs/multi_class_classification_info.json | python -m json.tool
{
"tasks": [
"label"
],
"vocabs": {
"label": [
0,
1,
2
]
},
"types": {
"label": "multi_class_classification"
}
}
[82]:
pyd_single_label_binary[0]
[82]:
{'static_indices': [24],
'static_measurement_indices': [5],
'dynamic': JointNestedRaggedTensorDict({'dim0/time_delta': array([60., 60., 60., 60., 60., 60., 60., 60.], dtype=float32), 'dim1/lengths': array([ 8, 8, 8, 9, 7, 10, 8, 9]), 'dim1/dynamic_measurement_indices': [array([1, 3, 2, 6, 6, 6, 6, 8], dtype=uint8), array([1, 3, 2, 2, 2, 8, 8, 8], dtype=uint8), array([1, 3, 2, 2, 6, 6, 8, 8], dtype=uint8), array([1, 3, 2, 2, 2, 6, 8, 8, 8], dtype=uint8), array([1, 3, 2, 2, 6, 8, 8], dtype=uint8), array([1, 3, 2, 2, 2, 6, 6, 8, 8, 8], dtype=uint8), array([1, 3, 2, 2, 6, 6, 8, 8], dtype=uint8), array([1, 3, 2, 2, 6, 6, 6, 8, 8], dtype=uint8)], 'dim1/dynamic_values': [array([ nan, -0.57425296, 1.9150734 , -1.6698846 , -0.07352565,
-0.16851047, nan, 0.6683647 ], dtype=float32), array([ nan, -0.57422704, 1.9366332 , 1.9862204 , 1.7706227 ,
0.4605351 , 0.6164083 , 0.5644519 ], dtype=float32), array([ nan, -0.57420105, 2.0703037 , 1.9797528 , -0.26349527,
-0.3584801 , 0.4605351 , 0.3046659 ], dtype=float32), array([ nan, -0.5741751 , 1.8309902 , 1.8956695 , 1.9064493 ,
-0.16851047, 0.20074913, 0.4605351 , 0.4085787 ], dtype=float32), array([ nan, -0.57414913, 1.9258534 , 1.9711286 , -0.3584801 ,
0.4605351 , 0.4605351 ], dtype=float32), array([ nan, -0.57412314, 1.9280092 , nan, 1.7663109 ,
-0.4534649 , -0.5484497 , 0.4605351 , 0.4085787 , 0.4605351 ],
dtype=float32), array([ nan, -0.5740972, nan, nan, -0.5484497,
-0.5484497, 0.4605351, 0.5644519], dtype=float32), array([ nan, -0.5740712, nan, nan, -0.5484497,
1.7221808, -0.4534649, 0.4085787, 0.4605351], dtype=float32)], 'dim1/dynamic_indices': [array([ 1, 16, 15, 28, 27, 27, 30, 55], dtype=uint8), array([ 3, 16, 15, 15, 15, 55, 55, 55], dtype=uint8), array([ 1, 16, 15, 15, 27, 27, 55, 55], dtype=uint8), array([ 1, 16, 15, 15, 15, 27, 55, 55, 55], dtype=uint8), array([ 1, 16, 15, 15, 27, 55, 55], dtype=uint8), array([ 1, 16, 15, 15, 15, 27, 27, 55, 55, 55], dtype=uint8), array([ 1, 16, 15, 15, 27, 27, 55, 55], dtype=uint8), array([ 1, 16, 15, 15, 27, 29, 27, 55, 55], dtype=uint8)], 'dim1/bounds': array([ 8, 16, 24, 33, 40, 50, 58, 67])}, schema={'dim1/time_delta': dtype('float32'), 'dim2/dynamic_indices': dtype('uint8'), 'dim2/dynamic_measurement_indices': dtype('uint8'), 'dim2/dynamic_values': dtype('float32')}, pre_raggedified=True),
'label': False}
ESGPT Tools¶
ESGPT also supports many additional tools that can operate over data in a unified way due to its standardized format.
Visualizing the data¶
Though this isn’t essential for any modeling, and isn’t yet a truly high-quality data visualization system, there is also some rudimentary code in the ESGPT repository for visualizing event data. Let’s run that now over our synthetic dataset
[83]:
from EventStream.data.visualize import Visualizer
from IPython.display import Image
[84]:
V = Visualizer(
age_col='age', dob_col='dob', static_covariates=['eye_color'], plot_by_age=True, n_age_buckets=50,
time_unit='1w'
)
figs = ESD.describe(viz_config=V)
for fig in figs:
display(Image(fig.to_image(format="png", width=600, height=350, scale=2)))
Dataset has 100 subjects, with 30.9 thousand events and 93.0 thousand measurements.
Dataset has 7 measurements:
eye_color: static, single_label_classification [...]
Vocabulary:
5 elements, 0.0% UNKs
Frequencies: █▄▂▁
Elements:
(50.0%) BROWN
(26.3%) BLUE
(16.3%) HAZEL
(7.5%) GREEN
department: dynamic, multi_label_classification [...]
Vocabulary:
4 elements, 0.0% UNKs
Frequencies: █▅▁
Elements:
(42.0%) PULMONARY
(35.0%) CARDIAC
(22.9%) ORTHOPEDIC
medication: dynamic, multi_label_classification [...]
Vocabulary:
6 elements, 0.0% UNKs
Frequencies: ██▇▇▁
Elements:
(23.0%) Motrin
(23.0%) Benadryl
(21.3%) Tylenol
(21.3%) Advil
(11.5%) motrin
HR: dynamic, univariate_regression observed 70.7%, [...]
Value is a float
temp: dynamic, univariate_regression observed 70.7%, [...]
Value is a float
lab_name: dynamic, multivariate_regression observed [...]
Value Types:
2 float
2 categorical_integer
1 integer
Vocabulary:
23 elements, 0.0% UNKs
Frequencies: █▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
Examples:
(83.8%) SpO2
(4.0%) potassium
(3.5%) creatinine
...
(0.1%) GCS__EQ_14
(0.1%) GCS__EQ_13
age: functional_time_dependent, univariate_regression [...]
Value is a float
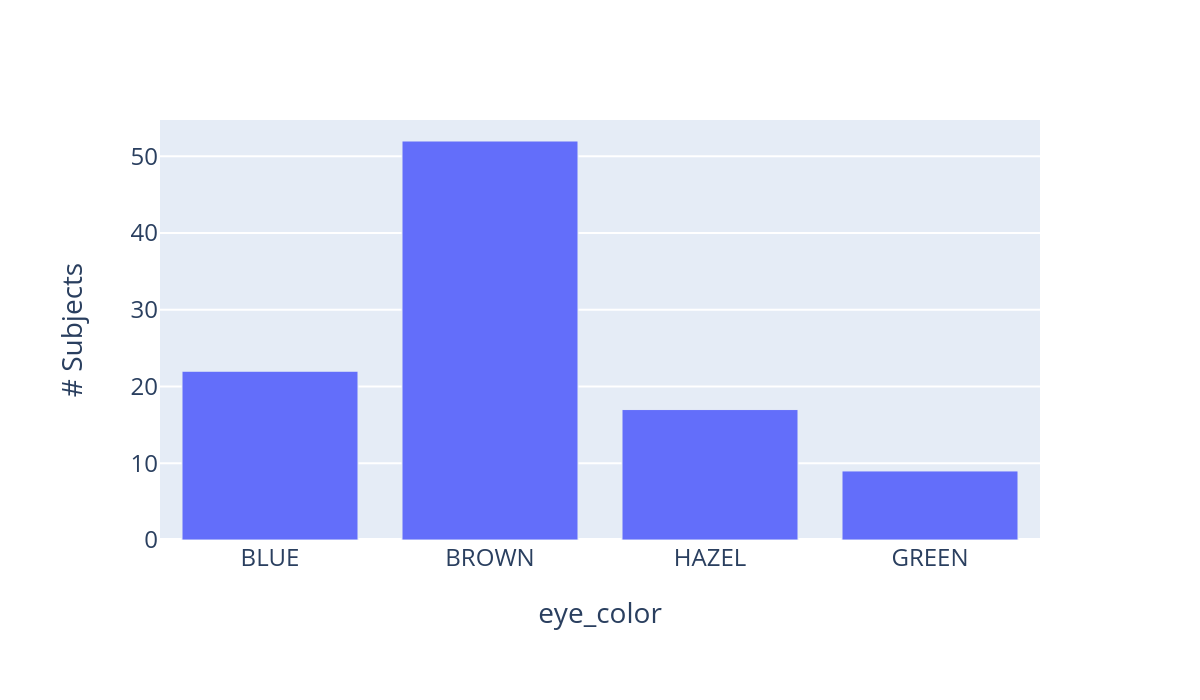
Training models¶
Next, we will show how you can train ESGPT style autoregressive models over these data. To begin, we need to know how these model architectures work:
How do model architectures work?¶
To see how model architectures work, consider the video tutorial below:
Training models with built in scripts¶
Now that you know how model architectures operate, let’s explore pre-training a toy model with the built-in pre-training script. It operates through a config file, much like the dataset building script does. Let’s see one such config file now:
[85]:
!cat sample_data/pretrain_CI.yaml
defaults:
- pretrain_config
- _self_
do_overwrite: false
seed: 1
config:
do_use_learnable_sinusoidal_ATE: false
do_split_embeddings: false
static_embedding_mode: sum_all
static_embedding_weight: 0.4
dynamic_embedding_weight: 0.5
do_normalize_by_measurement_index: false
structured_event_processing_mode: conditionally_independent
num_hidden_layers: 4
seq_attention_types: ["global", "local"]
seq_window_size: 4
TTE_generation_layer_type: log_normal_mixture
TTE_lognormal_generation_num_components: 2
head_dim: 8
num_attention_heads: 2
attention_dropout: 0.2
input_dropout: 0.2
resid_dropout: 0.2
intermediate_size: 128
optimization_config:
init_lr: 0.0001
end_lr_frac_of_init_lr: 0.01
end_lr: null
max_epochs: 2
batch_size: 32
validation_batch_size: 32
lr_frac_warmup_steps: 0.05
lr_decay_power: 2
weight_decay: 0.2
patience: null
gradient_accumulation: null
num_dataloader_workers: 1
data_config:
save_dir: ???
max_seq_len: 128
min_seq_len: 4
pretraining_metrics_config:
do_skip_all_metrics: false
do_validate_args: true
include_metrics:
TRAIN:
LOSS_PARTS: true
final_validation_metrics_config:
n_auc_thresholds: 25
do_skip_all_metrics: false
do_validate_args: true
include_metrics:
TUNING:
LOSS_PARTS: true
TTE:
MSE: true
MSLE: true
CLASSIFICATION:
AUROC:
- WEIGHTED
ACCURACY: true
AUPRC:
- WEIGHTED
REGRESSION:
MSE: true
HELD_OUT:
LOSS_PARTS: true
TTE:
MSE: true
MSLE: true
CLASSIFICATION:
AUROC:
- WEIGHTED
ACCURACY: true
REGRESSION:
MSE: true
EXPLAINED_VARIANCE: true
MSLE: true
trainer_config:
accelerator: cpu
devices: auto
detect_anomaly: true
log_every_n_steps: 1
experiment_dir: ???
wandb_logger_kwargs:
name: null
project: null
team: null
log_model: false
do_log_graph: false
do_final_validation_on_metrics: true
do_use_filesystem_sharing: false
There are a variety of aspects to this config, including model parameters in the config section, optimization parameters in the optimization_config section, metrics specifications in the pretraining_ and final_validation_ metrics_config sections, PyTorch Lightning trainer parameters in the trainer_config, and weights and biases logger parameters in the wandb_logger_kwargs section.
To understand each of these different config section, inspect the documentation for the generative modeling pre-training main function and the overall model configuration classes.
To run a pre-training model, we’ll use the below script:
PYTHONPATH=$(pwd):$PYTHONPATH ./scripts/pretrain.py \
--config-path="$(pwd)/sample_data/" \
--config-name=pretrain_CI \
"hydra.searchpath=[$(pwd)/configs]" \
data_config.save_dir=$(pwd)/sample_data/processed/sample \
experiment_dir=$(pwd)/sample_data/processed/PT_CI
[86]:
command = """\
PYTHONPATH=$(pwd):$PYTHONPATH ./scripts/pretrain.py \
--config-path="$(pwd)/sample_data/" \
--config-name=pretrain_CI \
"hydra.searchpath=[$(pwd)/configs]" \
data_config.save_dir=$(pwd)/sample_data/processed/sample \
experiment_dir=$(pwd)/sample_data/processed/PT_CI
"""
command_out = subprocess.run(command, shell=True, capture_output=True)
print(command_out.stdout.decode())
if command_out.returncode == 1:
print("Command Errored!")
print(command_out.stderr.decode())
Epoch 0: 100%|██████████| 3/3 [00:02<00:00, 1.43it/s, v_num=0]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: 0%| | 0/1 [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/1 [00:00<?, ?it/s]
Validation DataLoader 0: 100%|██████████| 1/1 [00:00<00:00, 21.21it/s]
Epoch 1: 100%|██████████| 3/3 [00:01<00:00, 1.64it/s, v_num=0]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: 0%| | 0/1 [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/1 [00:00<?, ?it/s]
Validation DataLoader 0: 100%|██████████| 1/1 [00:00<00:00, 12.17it/s]
Epoch 1: 100%|██████████| 3/3 [00:02<00:00, 1.40it/s, v_num=0]
Validation DataLoader 0: 100%|██████████| 1/1 [00:00<00:00, 10.60it/s]
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Validate metric DataLoader 0
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
tuning_HR_reg_NLL 3.070580005645752
tuning_TTE_reg_NLL 4.9825119972229
tuning_department_cls_NLL 0.7005310654640198
tuning_event_type_cls_NLL 3.3449509143829346
tuning_lab_name_cls_NLL 0.6937090158462524
tuning_lab_name_reg_NLL 1.9331945180892944
tuning_loss 18.53170394897461
tuning_medication_cls_NLL 0.6843563914299011
tuning_temp_reg_NLL 3.1218700408935547
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Testing DataLoader 0: 100%|██████████| 1/1 [00:00<00:00, 12.20it/s]
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Test metric DataLoader 0
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
held_out_HR_reg_NLL 2.6148171424865723
held_out_TTE_reg_NLL 4.943055152893066
held_out_department_cls_NLL 0.6871444582939148
held_out_event_type_cls_NLL 3.3685975074768066
held_out_lab_name_cls_NLL 0.6941561102867126
held_out_lab_name_reg_NLL 1.8249496221542358
held_out_loss 18.637100219726562
held_out_medication_cls_NLL 0.6871337890625
held_out_temp_reg_NLL 3.8172459602355957
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
2024-05-16 13:22:56.854 | WARNING | EventStream.transformer.config:__init__:629 - For a conditionally_independent model, measurements_per_dep_graph_level is not used; got []. Setting to None.
2024-05-16 13:22:56.854 | WARNING | EventStream.transformer.config:__init__:636 - For a conditionally_independent model, do_full_block_in_seq_attention is not used; got False. Setting to None.
2024-05-16 13:22:56.855 | WARNING | EventStream.transformer.config:__init__:643 - For a conditionally_independent model, do_full_block_in_dep_graph_attention is not used; got True. Setting to None.
2024-05-16 13:22:56.855 | WARNING | EventStream.transformer.config:__init__:656 - For a conditionally_independent model, dep_graph_window_size is not used; got 2. Setting to None.
Seed set to 1
2024-05-16 13:22:57.568 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:57.569 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:57.569 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:57.593 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:22:57.664 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 4 events
2024-05-16 13:22:57.665 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 4) from 80 to 80 rows and 80 to 80 subjects.
2024-05-16 13:22:57.670 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:22:57.671 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:22:57.672 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:22:57.705 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:22:57.713 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 4 events
2024-05-16 13:22:57.713 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 4) from 10 to 10 rows and 10 to 10 subjects.
2024-05-16 13:22:57.716 | INFO | EventStream.transformer.lightning_modules.generative_modeling:train:599 - Saving config files...
2024-05-16 13:22:57.717 | INFO | EventStream.transformer.lightning_modules.generative_modeling:train:604 - Writing to /home/mmd/Projects/EventStreamGPT/sample_data/processed/PT_CI/pretrain/2024-05-16_13-22-57/config.json
2024-05-16 13:22:57.720 | WARNING | EventStream.transformer.config:__init__:636 - For a conditionally_independent model, do_full_block_in_seq_attention is not used; got False. Setting to None.
2024-05-16 13:22:57.720 | WARNING | EventStream.transformer.config:__init__:643 - For a conditionally_independent model, do_full_block_in_dep_graph_attention is not used; got True. Setting to None.
2024-05-16 13:22:57.720 | WARNING | EventStream.transformer.config:__init__:656 - For a conditionally_independent model, dep_graph_window_size is not used; got 2. Setting to None.
You have turned on `Trainer(detect_anomaly=True)`. This will significantly slow down compute speed and is recommended only for model debugging.
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/home/mmd/mambaforge/envs/ESGPT_polars_0p20/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/logger_connector/logger_connector.py:75: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `lightning.pytorch` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
Missing logger folder: /home/mmd/Projects/EventStreamGPT/sample_data/processed/PT_CI/pretrain/2024-05-16_13-22-57/model_checkpoints/lightning_logs
| Name | Type | Params
-------------------------------------------------------------------
0 | tte_metrics | ModuleDict | 0
1 | metrics | ModuleDict | 0
2 | model | CIPPTForGenerativeSequenceModeling | 24.4 K
-------------------------------------------------------------------
24.3 K Trainable params
16 Non-trainable params
24.4 K Total params
0.097 Total estimated model params size (MB)
/home/mmd/mambaforge/envs/ESGPT_polars_0p20/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=7` in the `DataLoader` to improve performance.
/home/mmd/mambaforge/envs/ESGPT_polars_0p20/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=7` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=2` reached.
2024-05-16 13:23:03.817 | WARNING | EventStream.transformer.config:__init__:636 - For a conditionally_independent model, do_full_block_in_seq_attention is not used; got False. Setting to None.
2024-05-16 13:23:03.817 | WARNING | EventStream.transformer.config:__init__:643 - For a conditionally_independent model, do_full_block_in_dep_graph_attention is not used; got True. Setting to None.
2024-05-16 13:23:03.817 | WARNING | EventStream.transformer.config:__init__:656 - For a conditionally_independent model, dep_graph_window_size is not used; got 2. Setting to None.
2024-05-16 13:23:03.826 | INFO | EventStream.data.pytorch_dataset:__init__:141 - Reading vocabulary
2024-05-16 13:23:03.826 | INFO | EventStream.data.pytorch_dataset:__init__:144 - Reading splits & patient shards
2024-05-16 13:23:03.827 | INFO | EventStream.data.pytorch_dataset:__init__:147 - Setting measurement configs
2024-05-16 13:23:03.838 | INFO | EventStream.data.pytorch_dataset:__init__:150 - Reading patient descriptors
2024-05-16 13:23:03.842 | INFO | EventStream.data.pytorch_dataset:__init__:154 - Restricting to subjects with at least 4 events
2024-05-16 13:23:03.842 | INFO | EventStream.data.pytorch_dataset:filter_to_min_seq_len:351 - Filtered data due to sequence length constraint (>= 4) from 10 to 10 rows and 10 to 10 subjects.
/home/mmd/mambaforge/envs/ESGPT_polars_0p20/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=7` in the `DataLoader` to improve performance.
/home/mmd/mambaforge/envs/ESGPT_polars_0p20/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'test_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=7` in the `DataLoader` to improve performance.
2024-05-16 13:23:04.377 | INFO | EventStream.transformer.lightning_modules.generative_modeling:train:708 - Saving final metrics...
We can see that the model ran successfully, though of course on this synthetic data it does not learn any final validation metrics that indicate better than chance performance. With this, however, you have seen how to structure your own pre-training configuration file to run pre-training models yourself! Check back soon for more details on this process and for examples of other modeling tasks ESGPT supports, such as fine-tuning, hyperparameter tuning, and generation or zero-shot inference!